1CogAI Lab, Moscow, Russia 2MIRAI, Moscow, Russia
Top row shows all overlays at once: MIKASA-Robo memory → vision, MIKASA-Robo action → vision, LIBERO memory → vision, LIBERO action → vision.
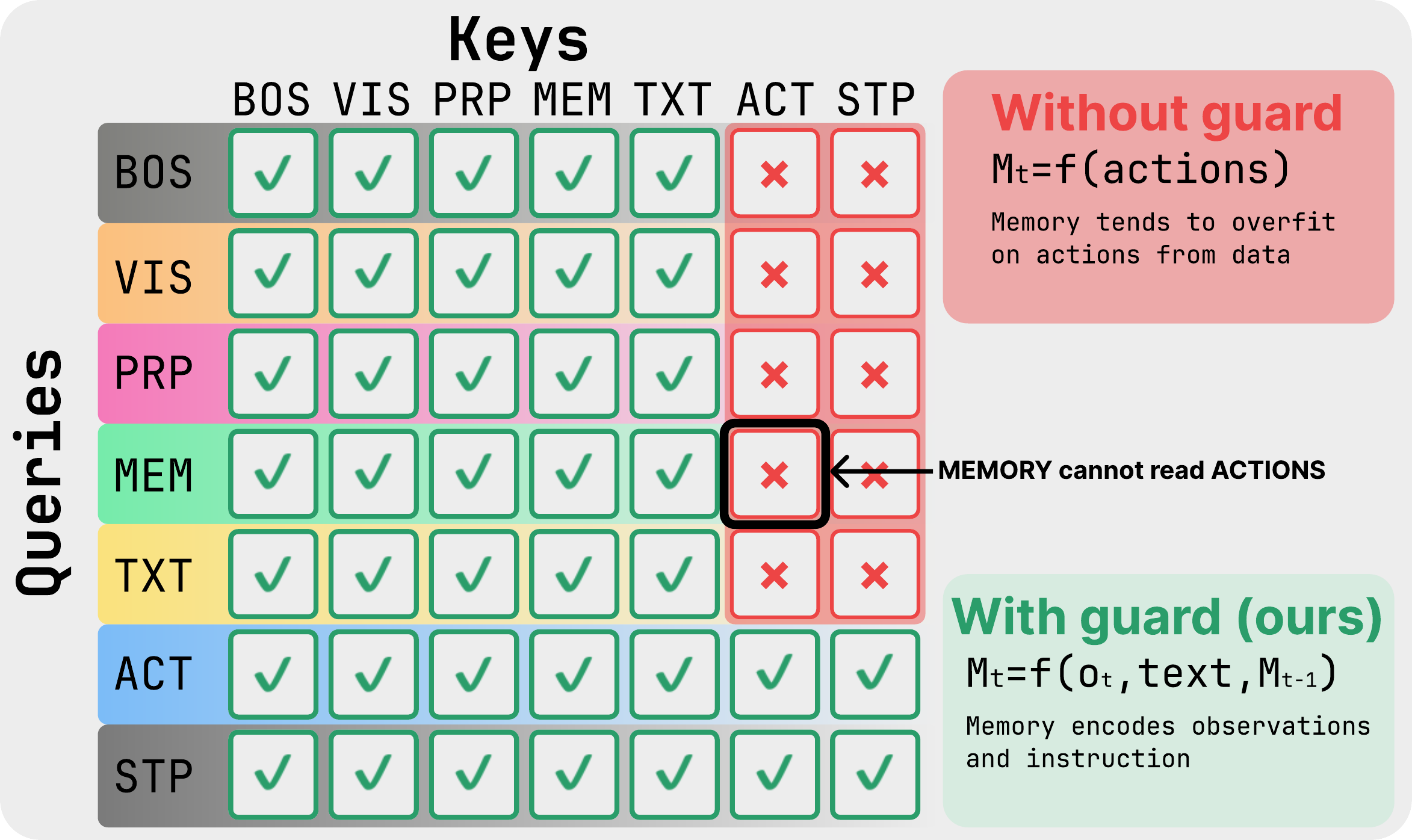
Vision-language-action (VLA) models predict chunks of future actions from the current observation, an assumption that fails under partial observability, where decisions depend on information no longer visible. Existing memory-augmented VLAs simultaneously introduce recurrence, retrieval, compression modules, auxiliary objectives, hierarchical memory, or task-specific architectural changes, so the contribution of recurrence itself remains entangled with surrounding machinery.
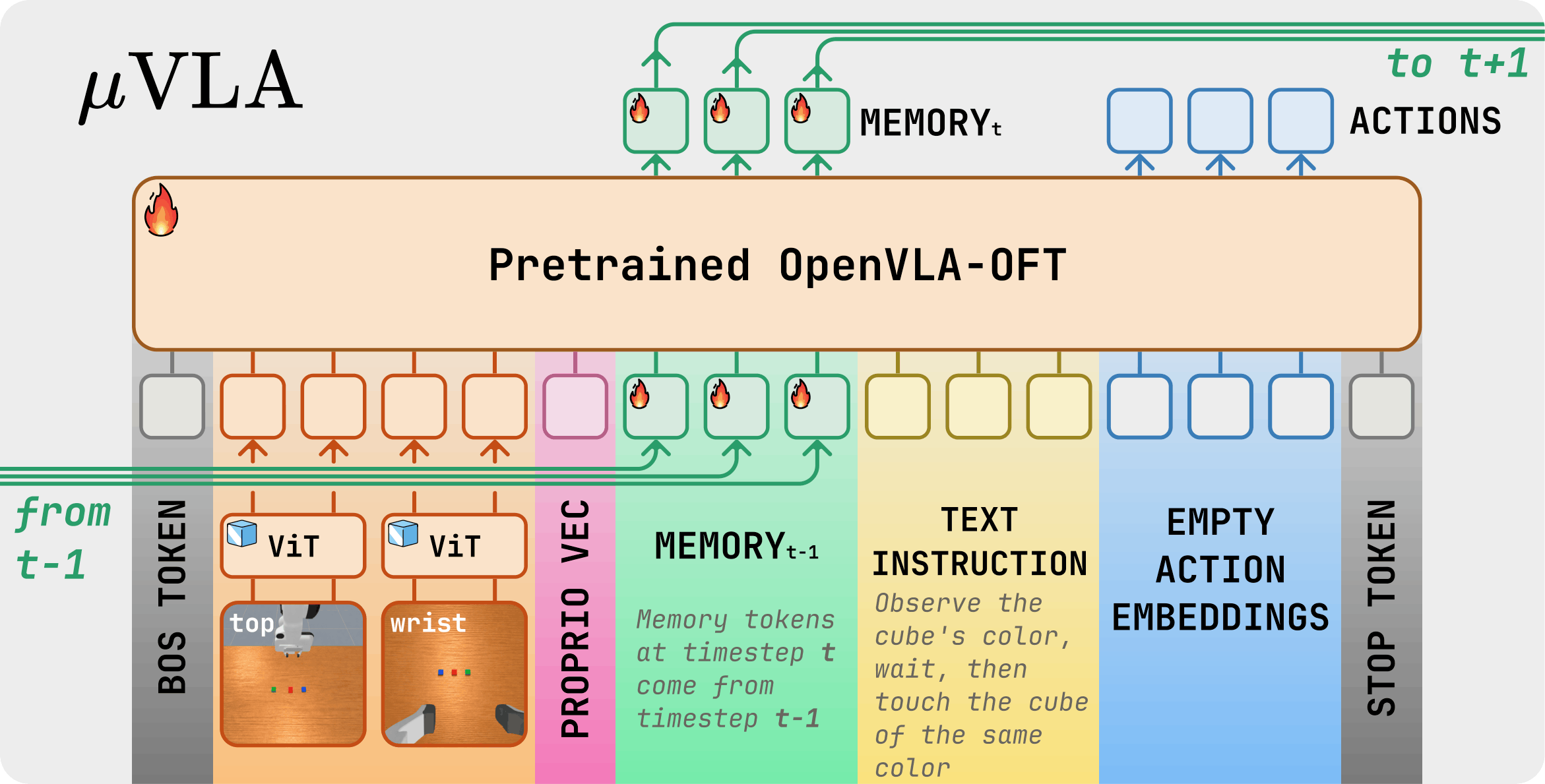
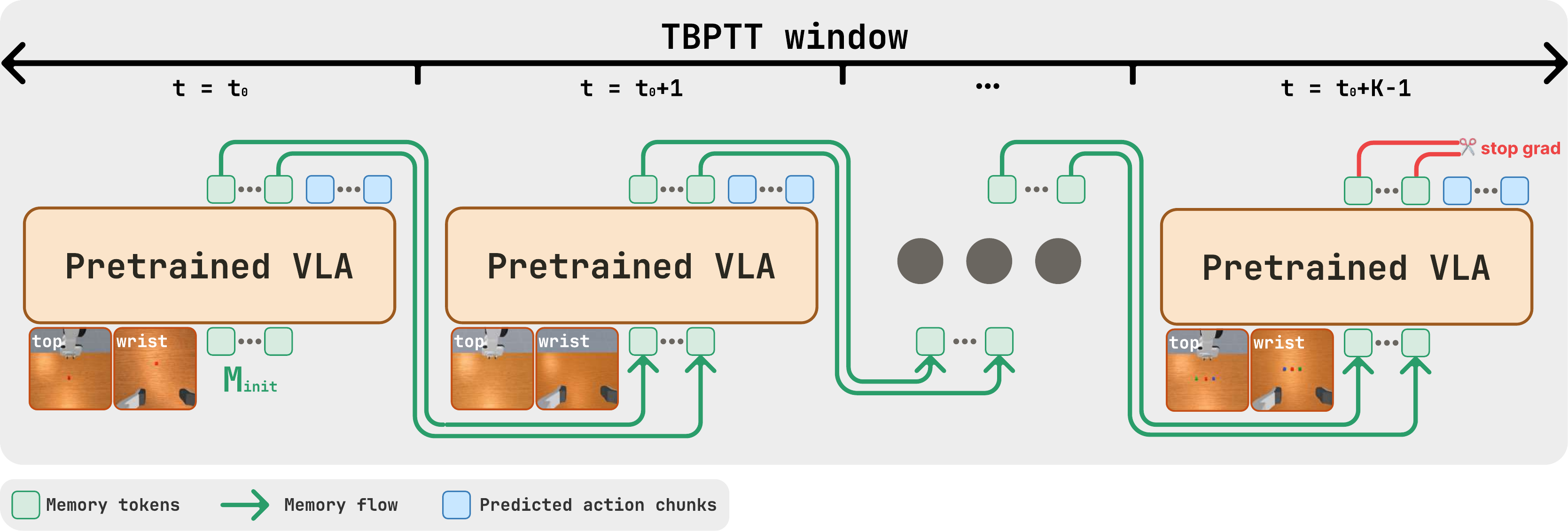
We present a controlled isolation study of recurrence in a strong pretrained VLA backbone. Our formulation augments the transformer with a small set of learnable memory tokens carried across timesteps and updated through self-attention, trained end to end with truncated backpropagation through time, with no auxiliary losses and no architectural changes. We instantiate this as μVLA, a family of OpenVLA-OFT variants parameterized by memory width m, TBPTT length K, and the memory update rule (cross-step gradients or a detached EMA), so that recurrence is the only varying factor.
On MIKASA-Robo, μVLA improves average success rate on five training tasks from 0.42 to 0.84 at the strongest setting and reaches 0.23 on held-out tasks with the same memory structure versus 0.07 for the memoryless baseline. On tasks requiring different memory structure, performance remains near baseline. On LIBERO, the strongest recurrent variant achieves 96.2% average success, indicating no regression under full observability.
Successful rollouts with attention projected onto visual patches. By default the attention maps are aggregated as mean over layers and heads. Per-layer mode keeps the same rollout but replaces either lower row independently with mean-over-heads attention from a selected transformer layer.



Aggregated attention rollouts and frame-by-frame overlays for successful LIBERO episodes. Choose a suite, task, and episode; attention maps are mean over layers and heads.



100 deterministic episodes per environment; mean reported. OpenVLA-OFT† uses the episodic dataloader. The (+1st obs.) column appends the first observation at every timestep and acts as an oracle-style upper bound for first-frame cue tasks. μVLA columns use m=64 unless marked m=1.
| Environment | π0.5 | OpenVLA -OFT | OpenVLA -OFT† | m=1 K=8Ours | m=64 K=8Ours | K=2Ours | K=1Ours | EMAOurs | EMA full maskOurs | single-task RC5Ours | OpenVLA-OFT (+1st obs.)Oracle |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Training tasks (in-distribution) | |||||||||||
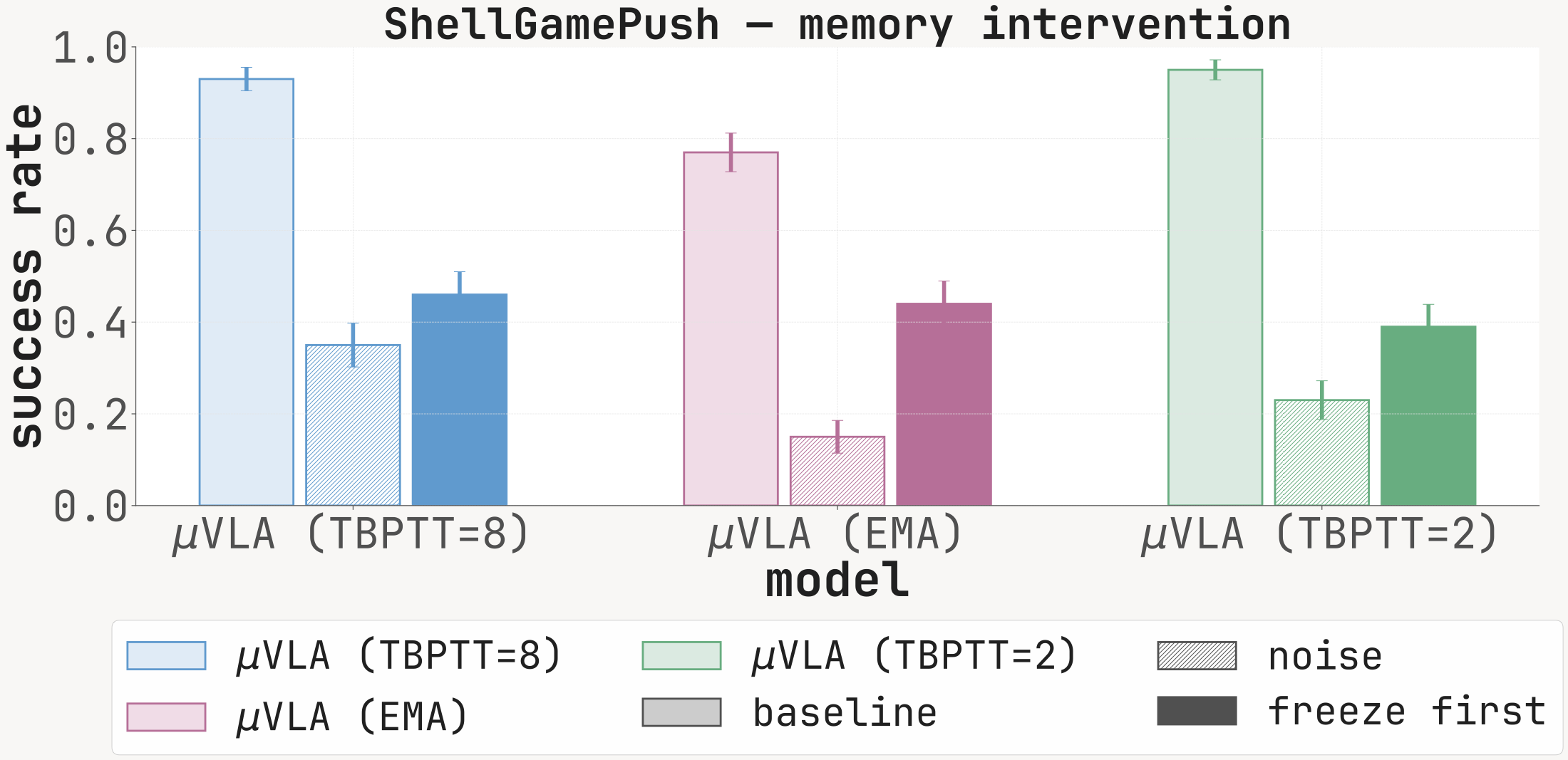
| ShellGamePush | 0.86 | 0.83 | 0.90 | 0.91 | 0.83 | 0.95 | 0.93 | 0.77 | 0.94 | 0.13 | 0.99 |
| InterceptMedium | 0.40 | 0.36 | 0.39 | 0.49 | 0.55 | 0.47 | 0.44 | 0.55 | 0.56 | 0.01 | 0.45 |
| TakeItBack | 0.85 | 0.83 | 0.87 | 0.97 | 0.98 | 0.99 | 0.99 | 0.99 | 0.99 | 0.00 | 0.94 |
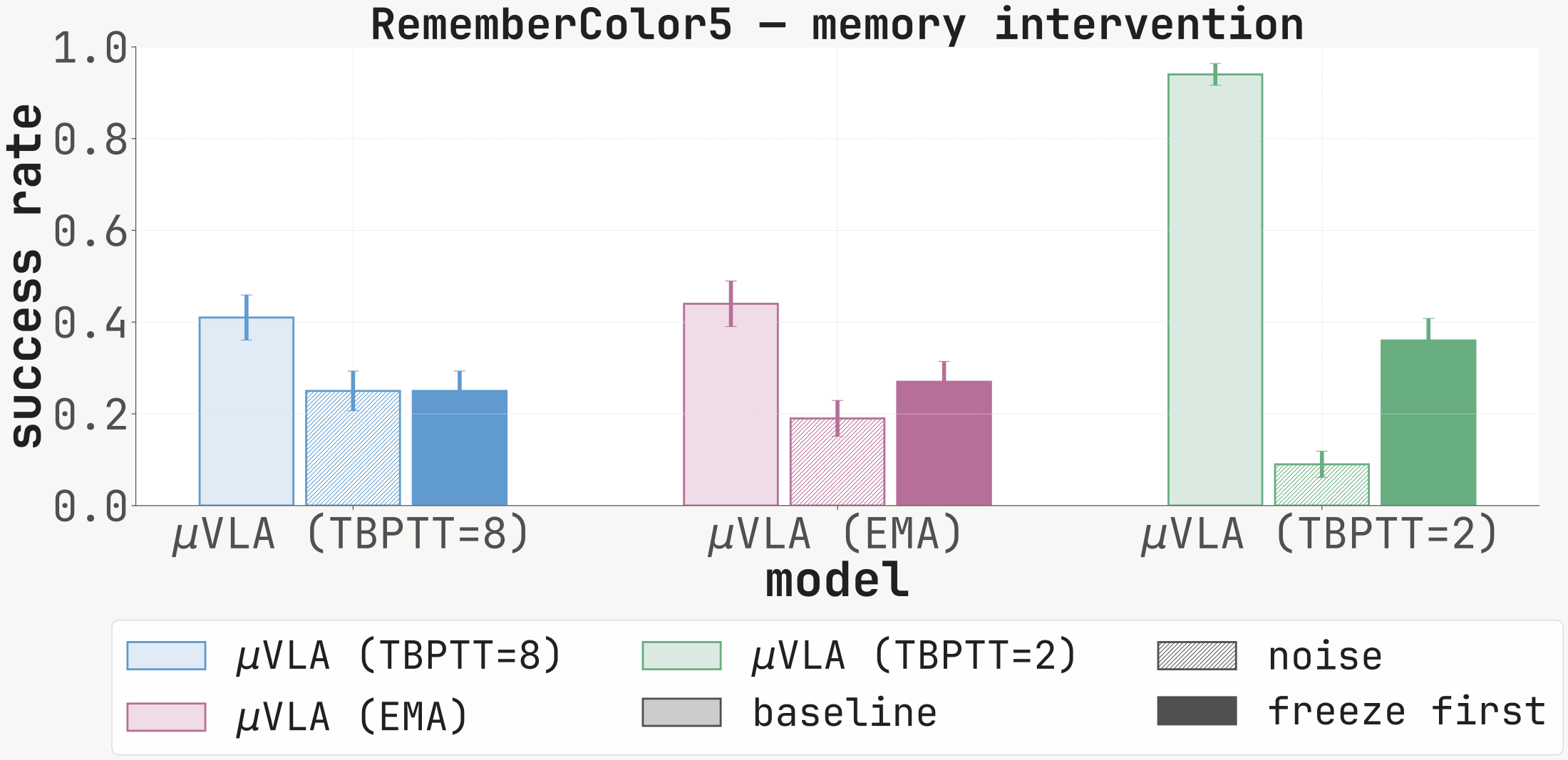
| RememberColor5 | 0.12 | 0.04 | 0.09 | 0.24 | 0.35 | 0.93 | 0.40 | 0.44 | 0.25 | 0.16 | 0.96 |
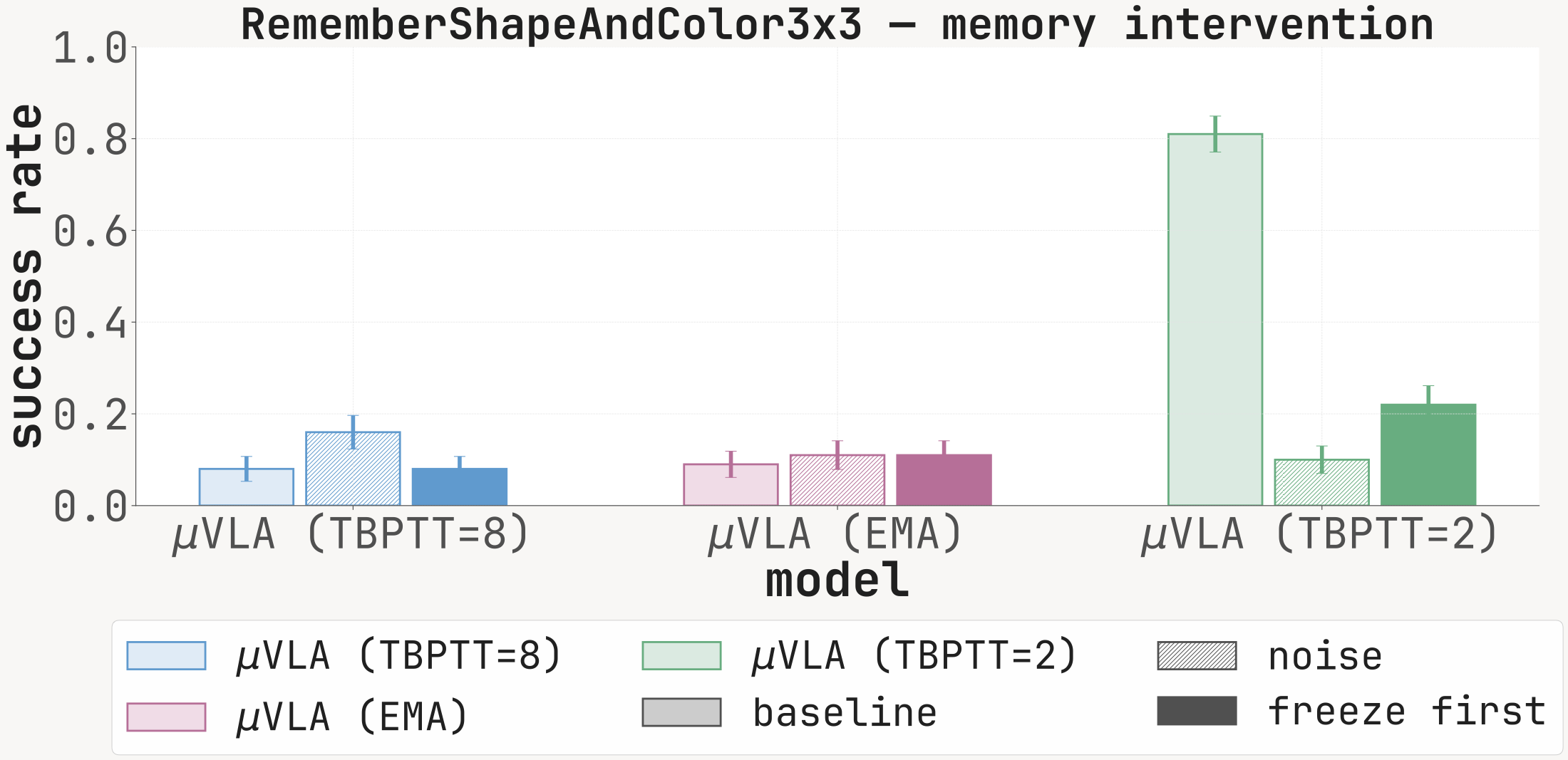
| RememberShapeAndColor3x3 | 0.10 | 0.03 | 0.13 | 0.08 | 0.12 | 0.86 | 0.09 | 0.09 | 0.10 | 0.05 | 0.91 |
| Average (5 envs) | 0.46 | 0.42 | 0.48 | 0.54 | 0.57 | 0.84 | 0.57 | 0.57 | 0.57 | 0.07 | 0.85 |
| Held-out, matched memory semantics | |||||||||||
| ShellGameTouch | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.07 | 0.00 |
| ShellGamePick | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.01 | 0.00 | 0.01 | 0.00 | 0.01 |
| InterceptSlow | 0.05 | 0.05 | 0.04 | 0.05 | 0.06 | 0.07 | 0.06 | 0.05 | 0.06 | 0.02 | 0.04 |
| InterceptFast | 0.10 | 0.00 | 0.33 | 0.21 | 0.28 | 0.27 | 0.19 | 0.28 | 0.35 | 0.00 | 0.31 |
| InterceptGrabSlow | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| InterceptGrabMedium | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| InterceptGrabFast | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| RememberColor3 | 0.07 | 0.00 | 0.19 | 0.30 | 0.41 | 0.92 | 0.38 | 0.37 | 0.28 | 0.30 | 0.91 |
| RememberColor9 | 0.05 | 0.03 | 0.11 | 0.08 | 0.11 | 0.41 | 0.09 | 0.11 | 0.11 | 0.05 | 0.47 |
| RememberShapeAndColor3x2 | 0.07 | 0.03 | 0.09 | 0.06 | 0.11 | 0.59 | 0.11 | 0.12 | 0.04 | 0.11 | 0.62 |
| RememberShapeAndColor5x3 | 0.04 | 0.01 | 0.06 | 0.12 | 0.04 | 0.28 | 0.15 | 0.08 | 0.07 | 0.09 | 0.29 |
| Average (11 envs) | 0.03 | 0.01 | 0.07 | 0.07 | 0.09 | 0.23 | 0.09 | 0.09 | 0.08 | 0.06 | 0.24 |
| Held-out, novel memory semantics | |||||||||||
| RememberShape3 | 0.05 | 0.00 | 0.08 | 0.21 | 0.27 | 0.35 | 0.35 | 0.28 | 0.22 | 0.29 | 0.46 |
| RememberShape5 | 0.04 | 0.00 | 0.11 | 0.20 | 0.21 | 0.46 | 0.20 | 0.20 | 0.20 | 0.16 | 0.40 |
| RememberShape9 | 0.00 | 0.00 | 0.11 | 0.14 | 0.11 | 0.30 | 0.09 | 0.11 | 0.13 | 0.06 | 0.29 |
| RotateLenientPos | 0.01 | 0.06 | 0.04 | 0.00 | 0.01 | 0.00 | 0.00 | 0.01 | 0.01 | 0.02 | 0.02 |
| RotateLenientPosNeg | 0.00 | 0.03 | 0.08 | 0.01 | 0.03 | 0.02 | 0.06 | 0.00 | 0.10 | 0.02 | 0.07 |
| RotateStrictPos | 0.00 | 0.00 | 0.04 | 0.03 | 0.02 | 0.00 | 0.04 | 0.00 | 0.02 | 0.02 | 0.05 |
| RotateStrictPosNeg | 0.00 | 0.00 | 0.03 | 0.01 | 0.01 | 0.00 | 0.06 | 0.00 | 0.03 | 0.04 | 0.04 |
| Average (7 envs) | 0.00 | 0.01 | 0.07 | 0.09 | 0.09 | 0.16 | 0.11 | 0.09 | 0.10 | 0.09 | 0.19 |
| Avg. over 23 environments | 0.10 | 0.10 | 0.16 | 0.18 | 0.20 | 0.34 | 0.20 | 0.19 | 0.19 | 0.07 | 0.36 |
Success rates are reported per task. CronusVLA and MemoryVLA results are from the MemoryVLA paper; memory-augmented models are shaded in the paper.
| Model | InterceptMedium | RememberColor3 | RememberColor5 | RememberColor9 | Avg. |
|---|---|---|---|---|---|
| SpatialVLA | 0.27 | 0.27 | 0.17 | 0.11 | 0.21 |
| OpenVLA-OFT | 0.14 | 0.59 | 0.16 | 0.06 | 0.24 |
| π0 | 0.42 | 0.35 | 0.22 | 0.15 | 0.29 |
| CronusVLA | 0.05 | 0.31 | 0.13 | 0.09 | 0.15 |
| MemoryVLA | 0.24 | 0.44 | 0.30 | 0.20 | 0.30 |
| μVLA (ours) | 0.56 | 0.92 | 0.93 | 0.41 | 0.71 |
Success rates (%) are reported for the four LIBERO suites and their average. * denotes memory-augmented VLA models.
| Method | Spatial | Object | Goal | Long-10 | Avg. |
|---|---|---|---|---|---|
| Diffusion Policy | 78.3 | 92.5 | 68.3 | 50.5 | 72.4 |
| Octo | 78.9 | 85.7 | 84.6 | 51.1 | 75.1 |
| OpenVLA | 84.7 | 88.4 | 79.2 | 53.7 | 75.9 |
| SpatialVLA | 88.2 | 89.9 | 78.6 | 55.5 | 71.7 |
| UniACT | 77.0 | 87.0 | 77.0 | 70.0 | 76.8 |
| π0 | 96.8 | 98.8 | 95.8 | 85.2 | 94.2 |
| π0-FAST | 96.4 | 96.8 | 88.6 | 60.2 | 85.0 |
| CogACT | 97.2 | 98.0 | 90.2 | 88.8 | 93.2 |
| OpenVLA-OFT | 97.6 | 98.4 | 97.9 | 94.5 | 97.1 |
| CronusVLA* | 90.1 | 94.7 | 91.3 | 68.7 | 86.2 |
| MemoryVLA* | 98.4 | 98.4 | 96.4 | 93.4 | 96.5 |
| μVLA (m=64, K=8, ours) | 93.0 | 99.4 | 96.6 | 95.8 | 96.2 |
| μVLA (m=64, EMA, ours) | 70.8 | 64.4 | 6.6 | 37.2 | 44.8 |
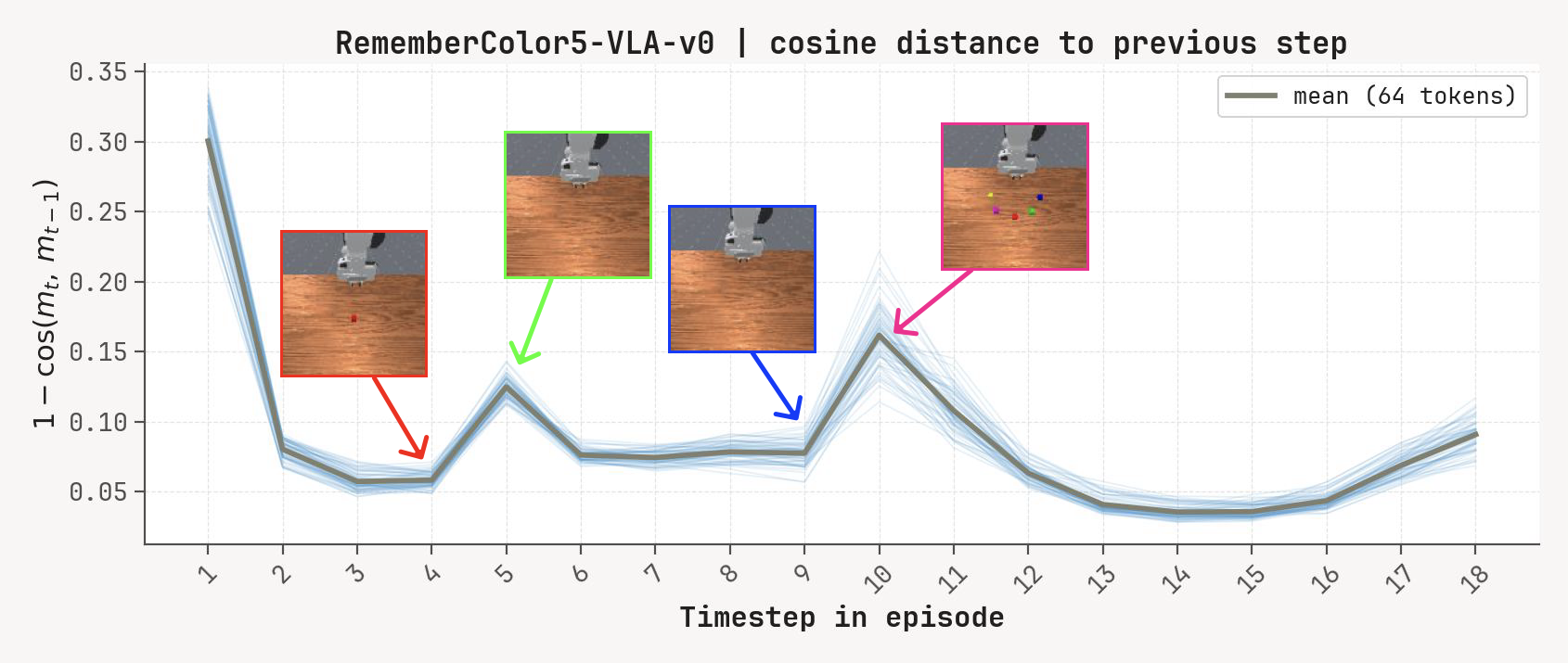
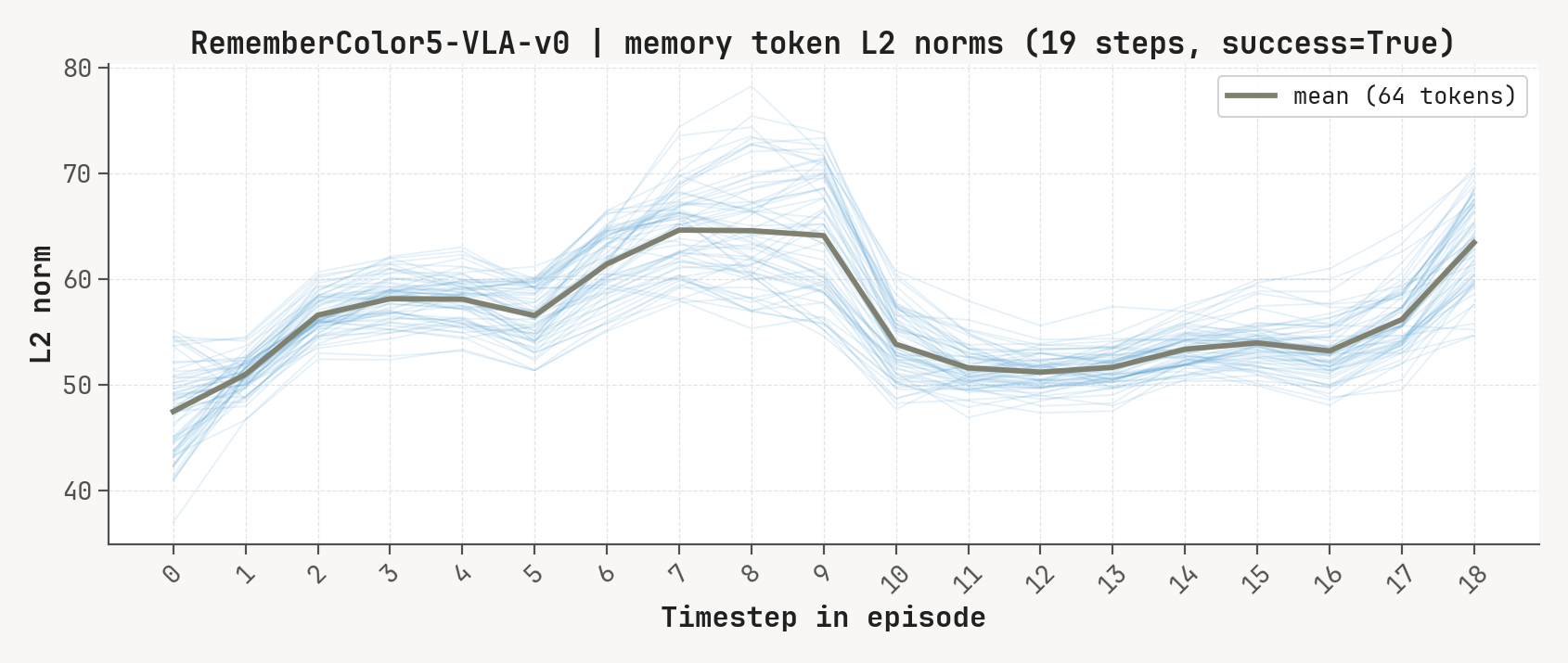
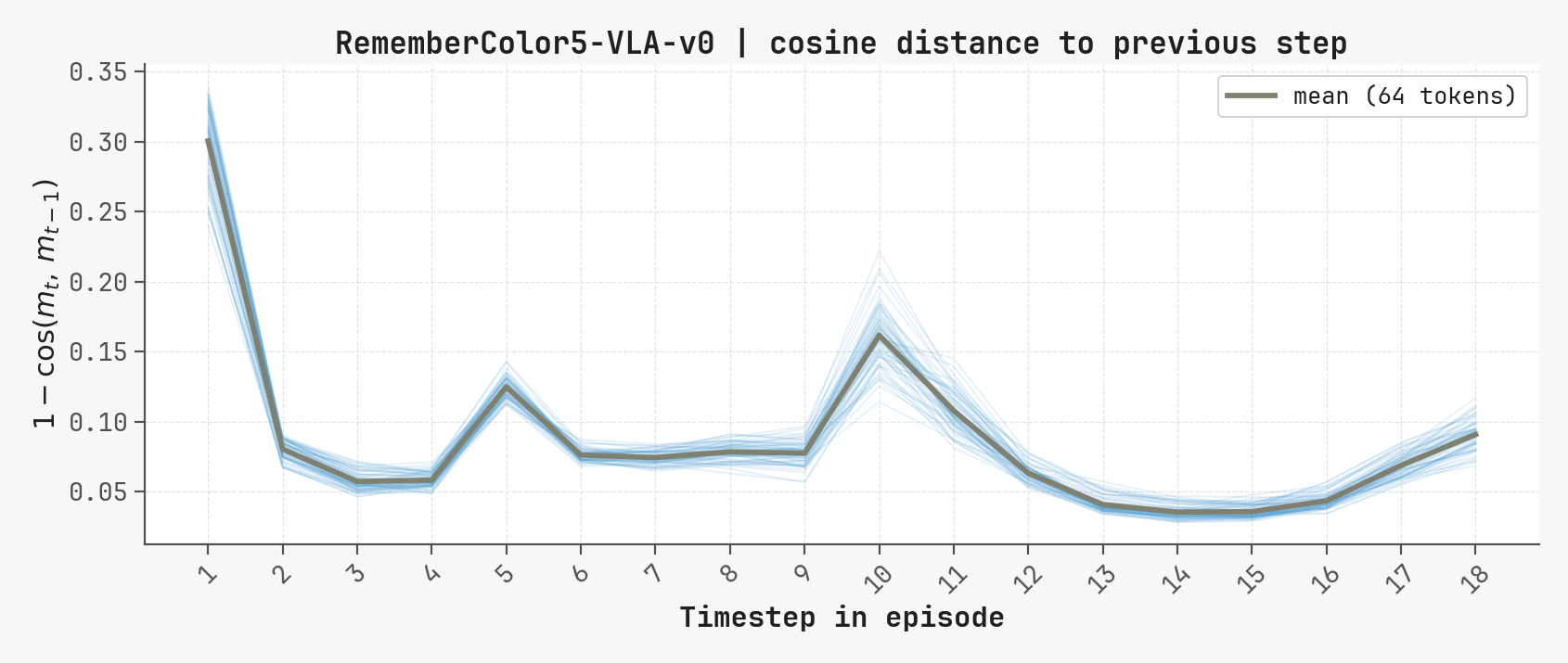
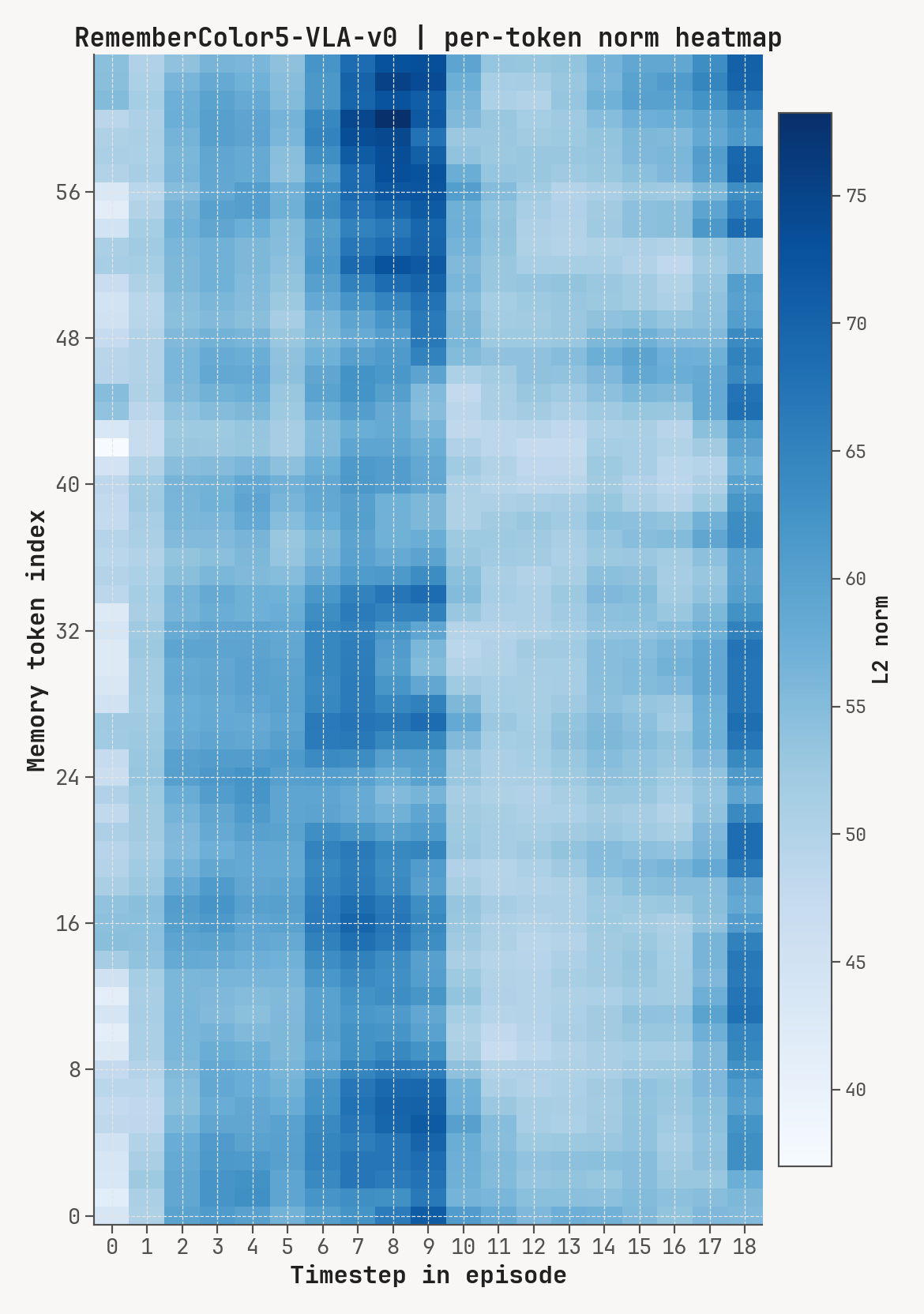
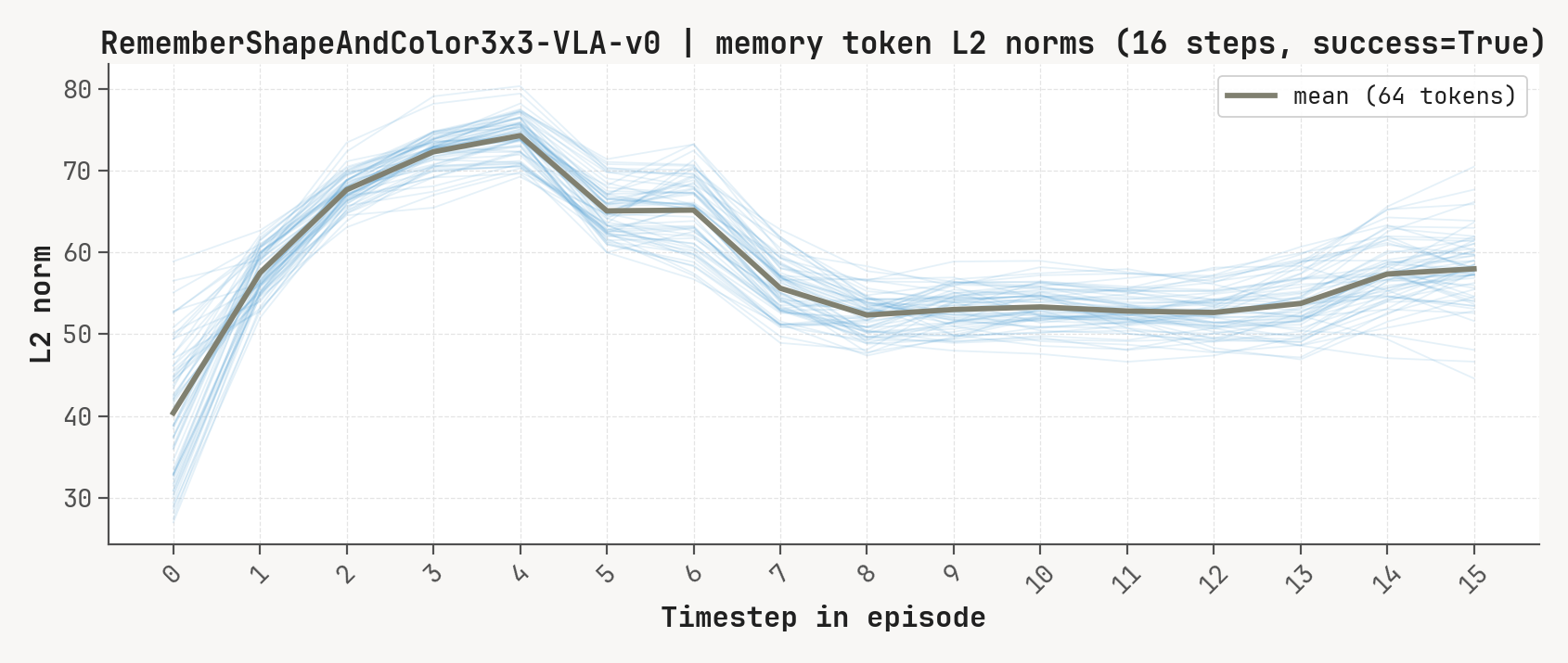
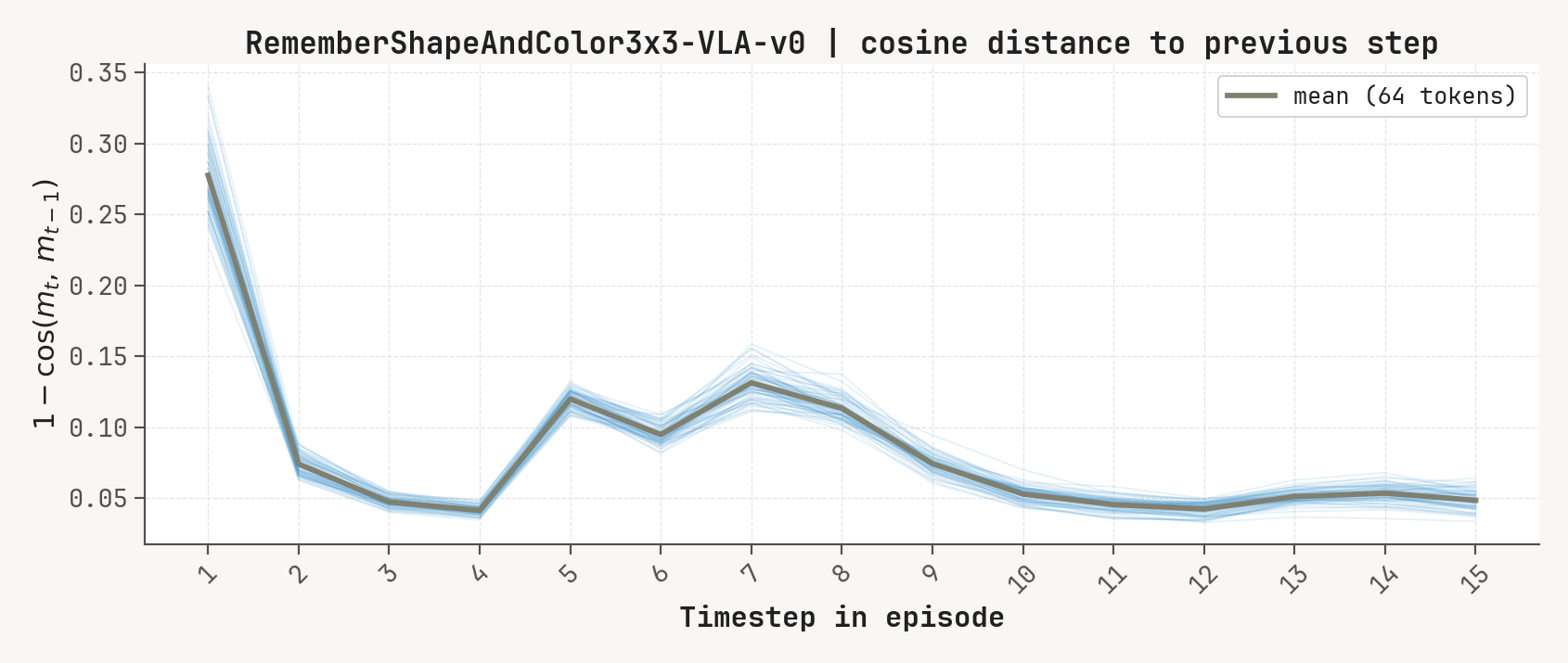
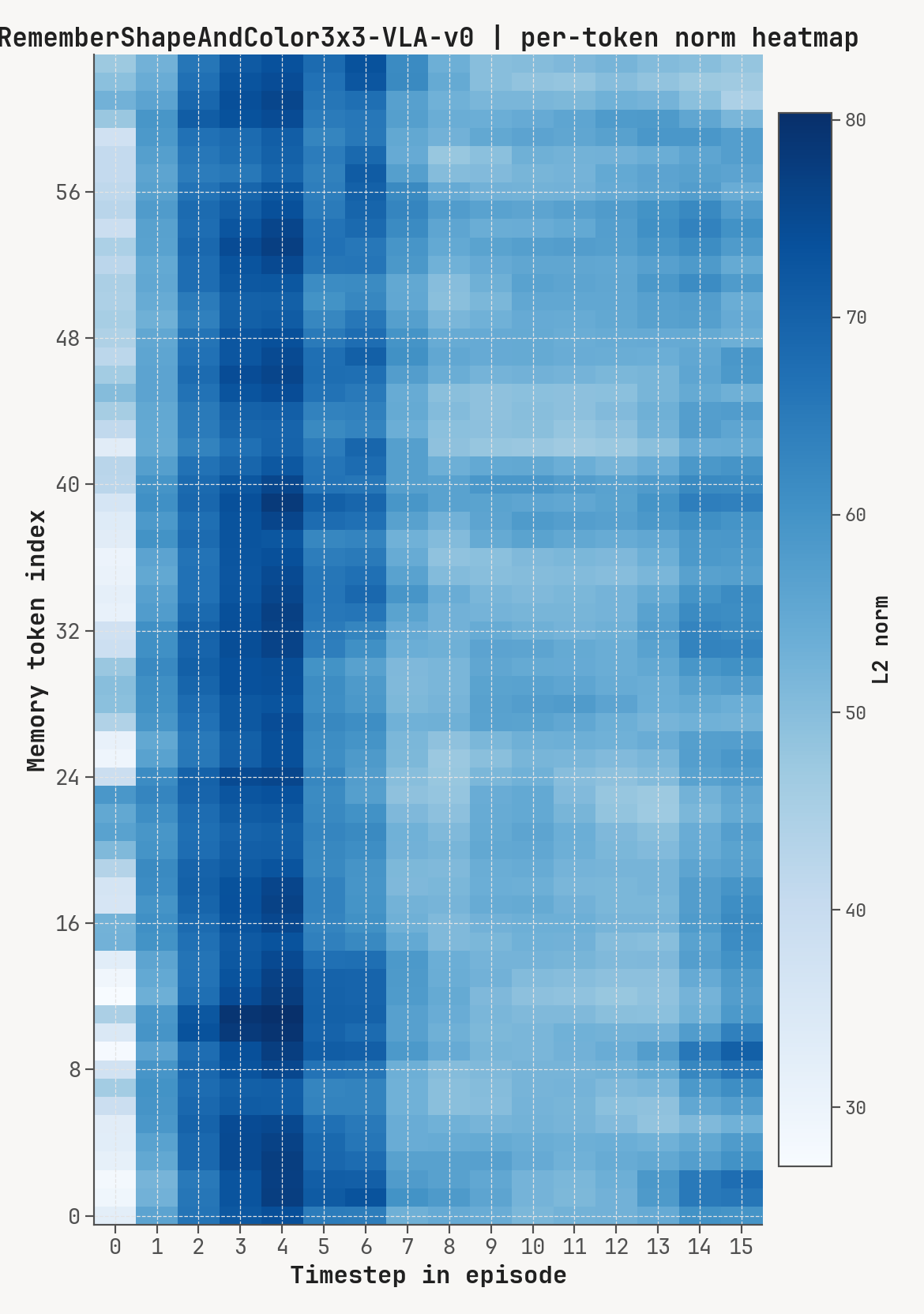
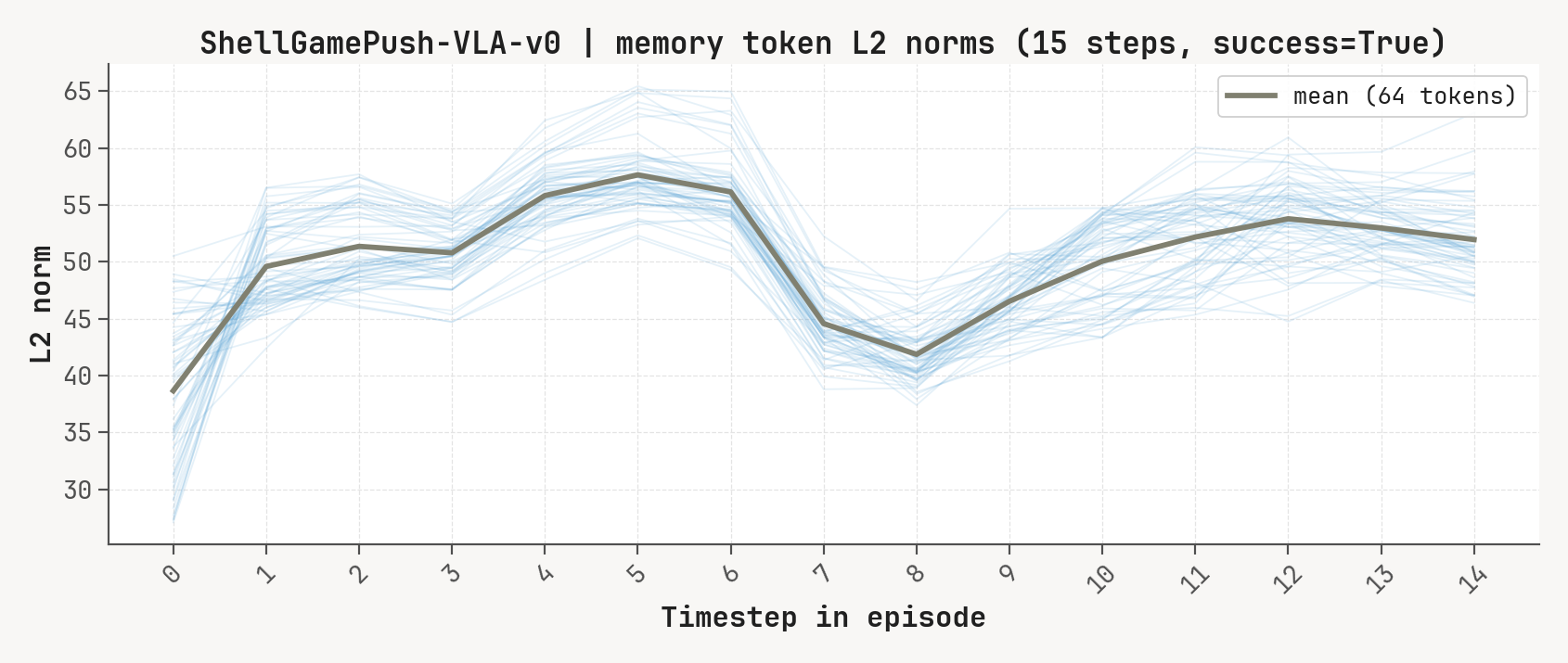
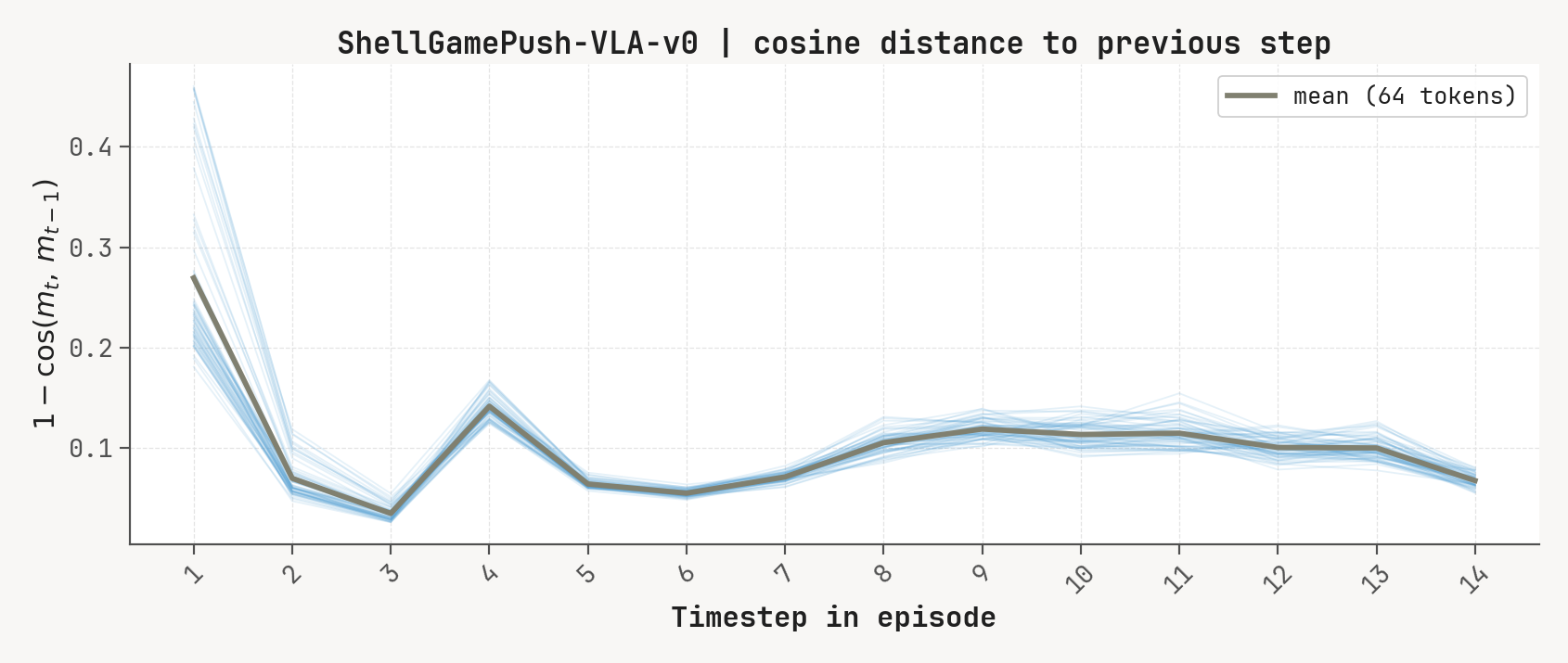
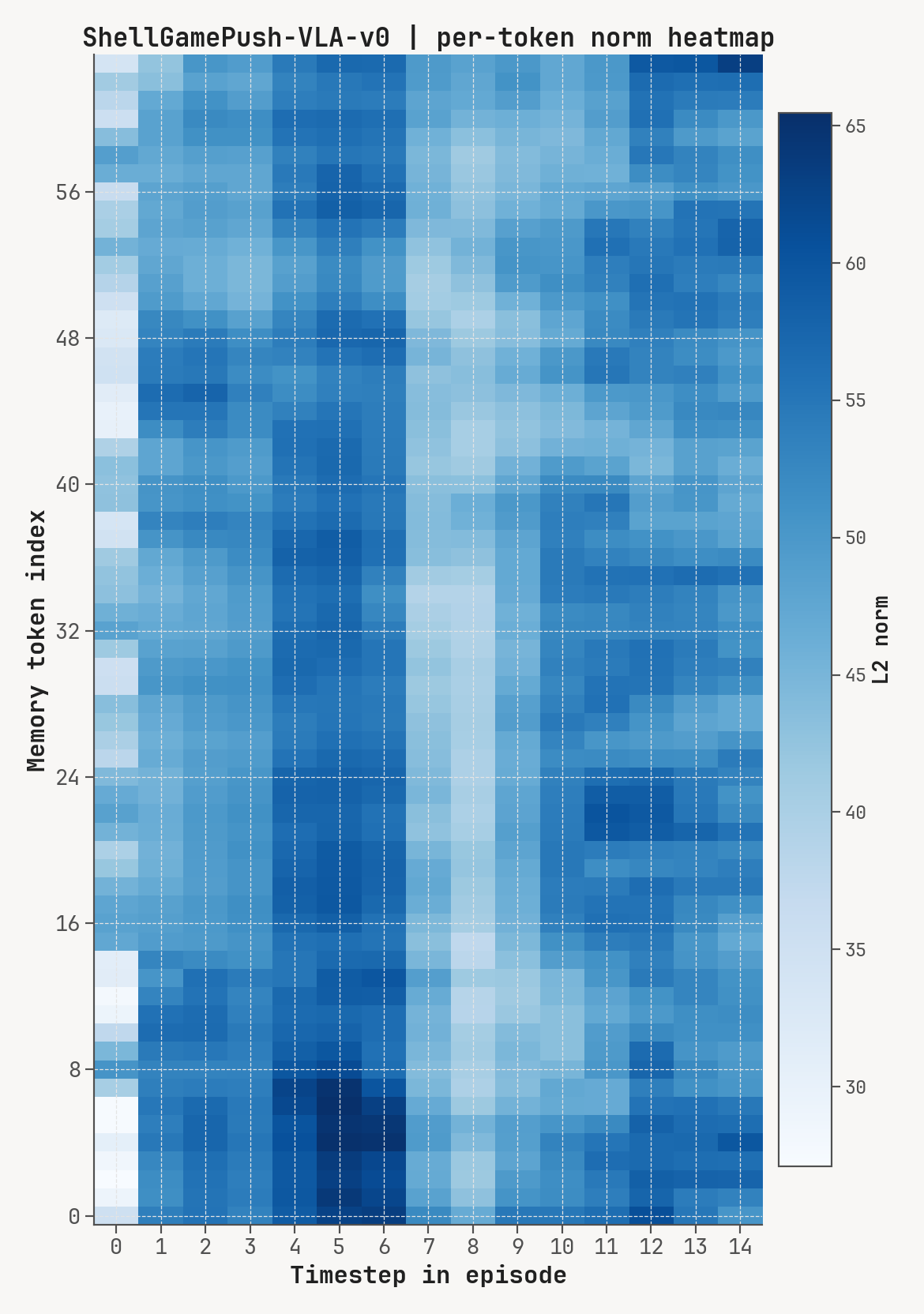
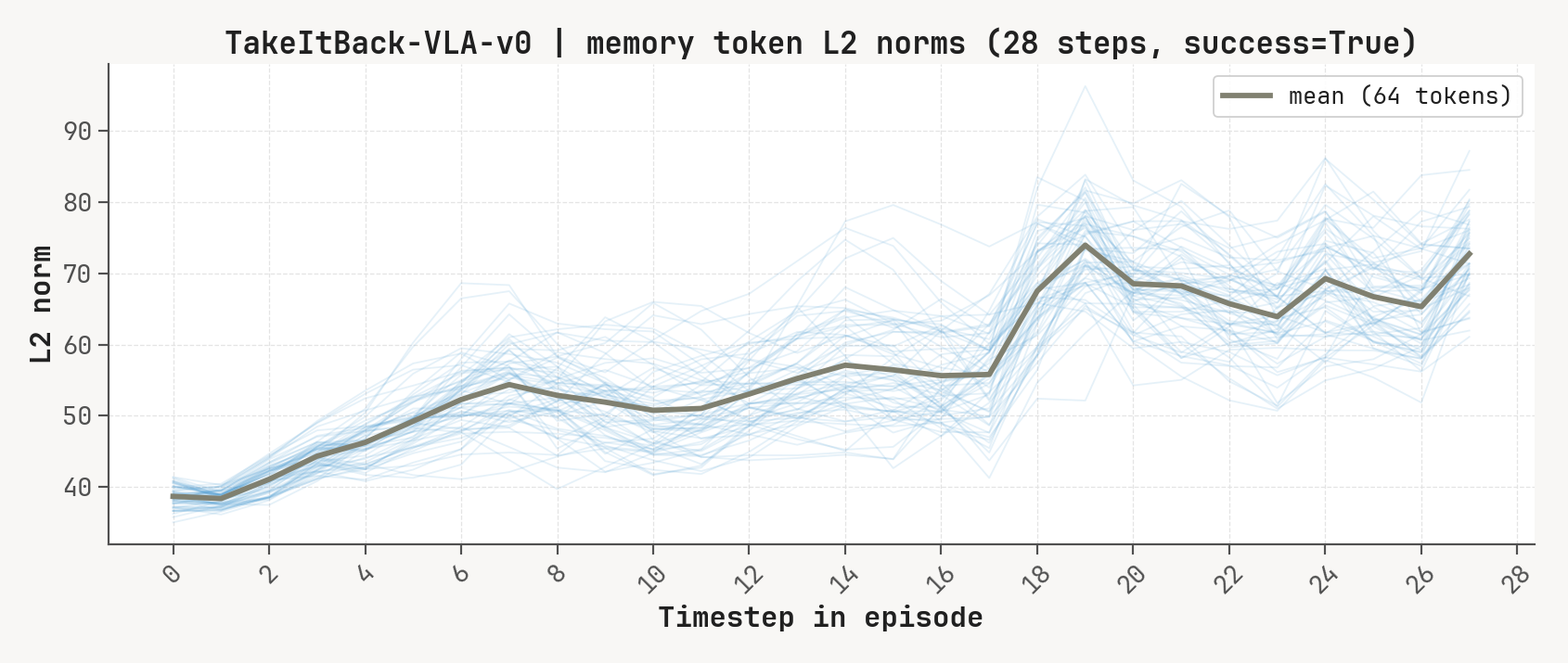
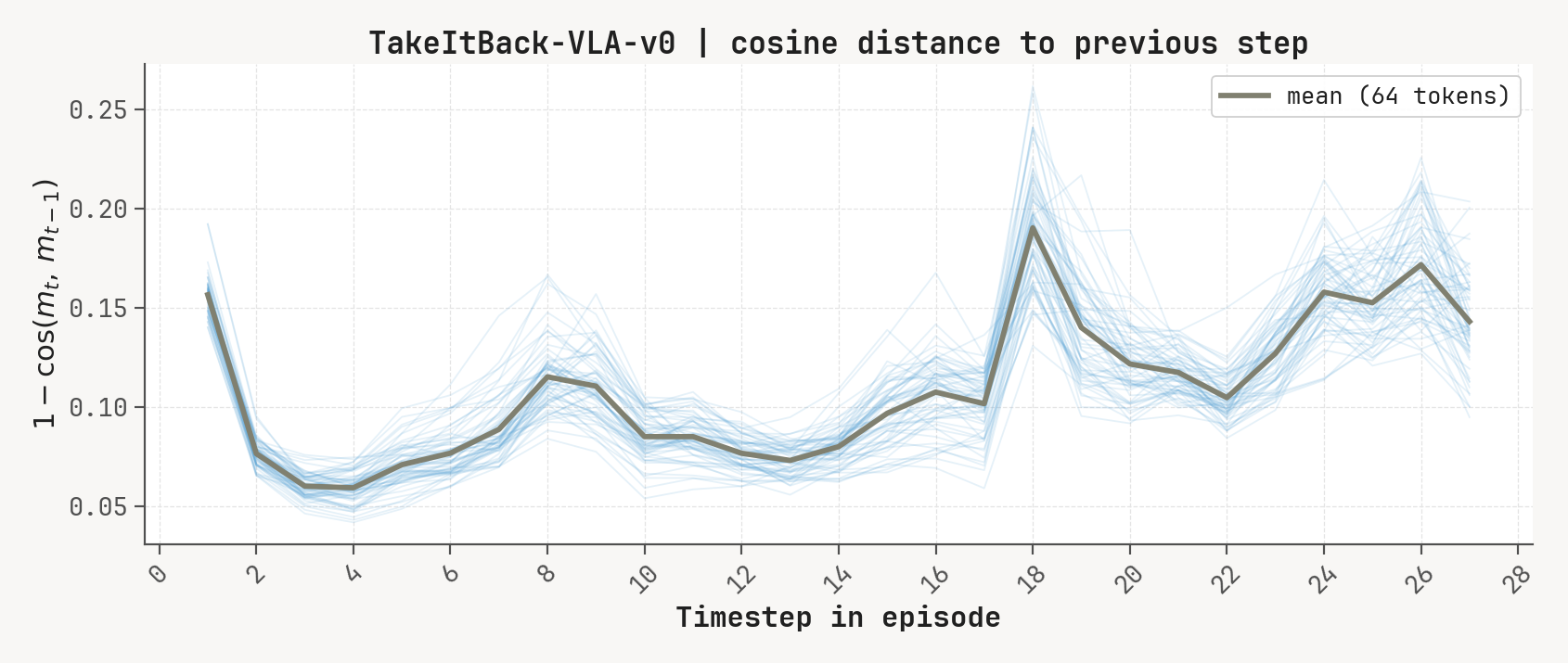
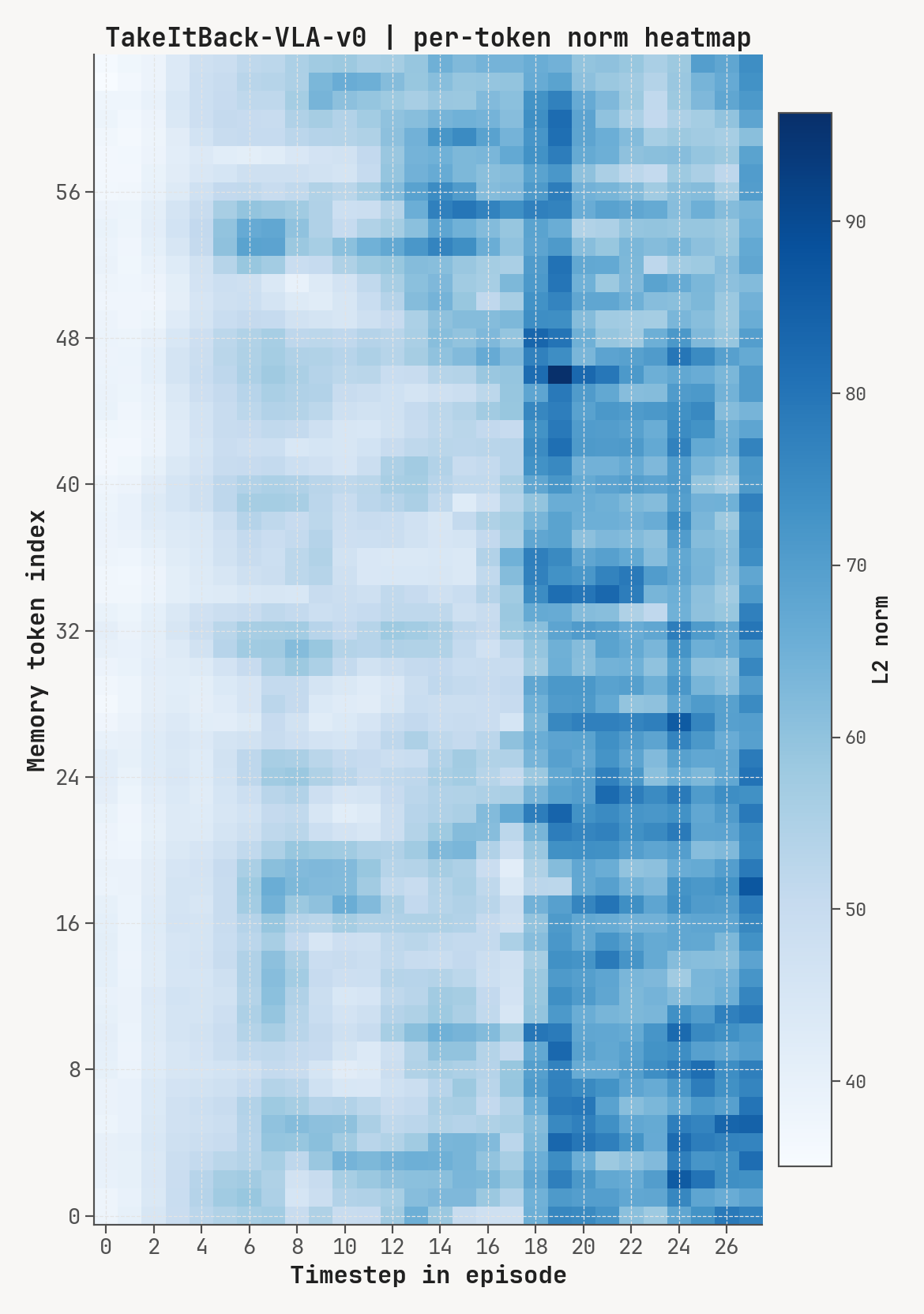
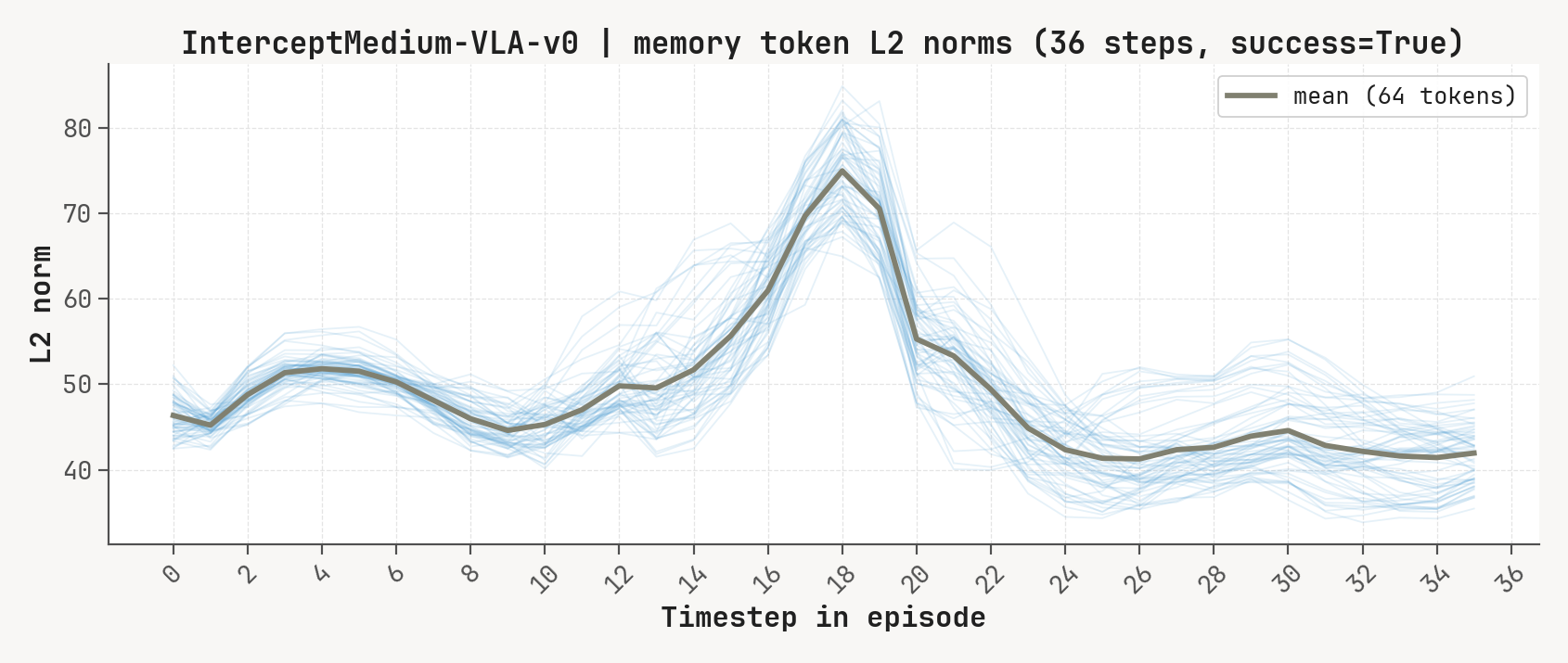
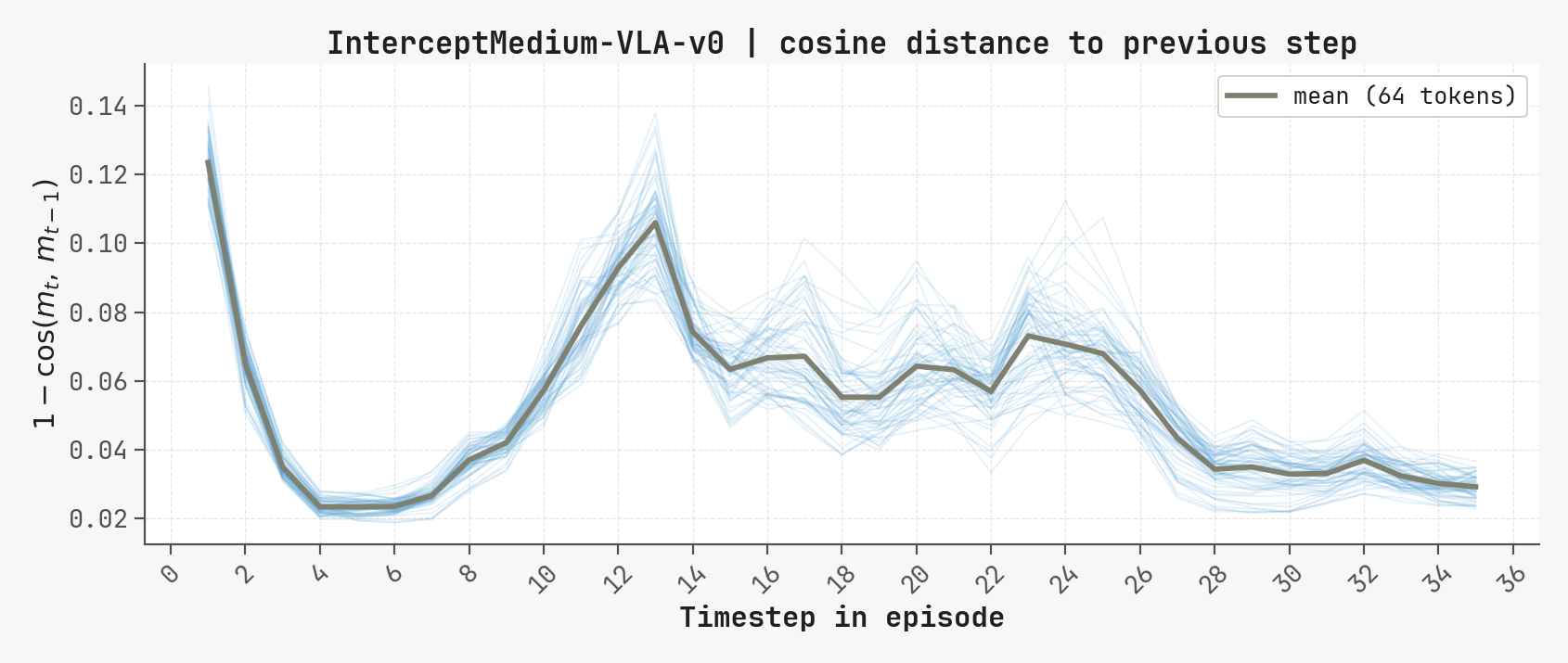
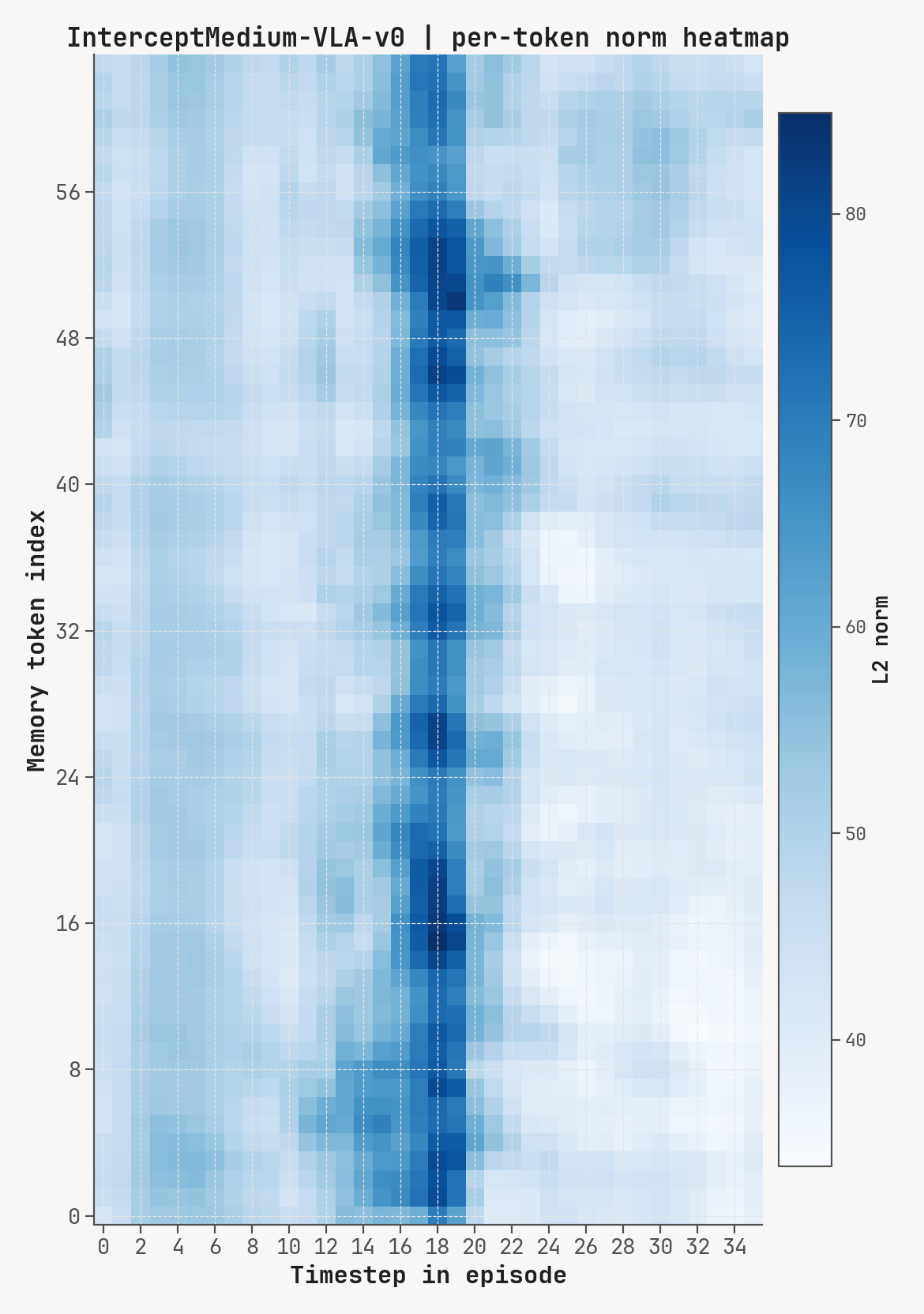
Per-token L2 norms, cosine-distance-to-previous, and rollout for a successful episode at K=2, m=64. Cue-recall tasks show a single dominant write event followed by a secondary bump aligned with the cue-removal window.





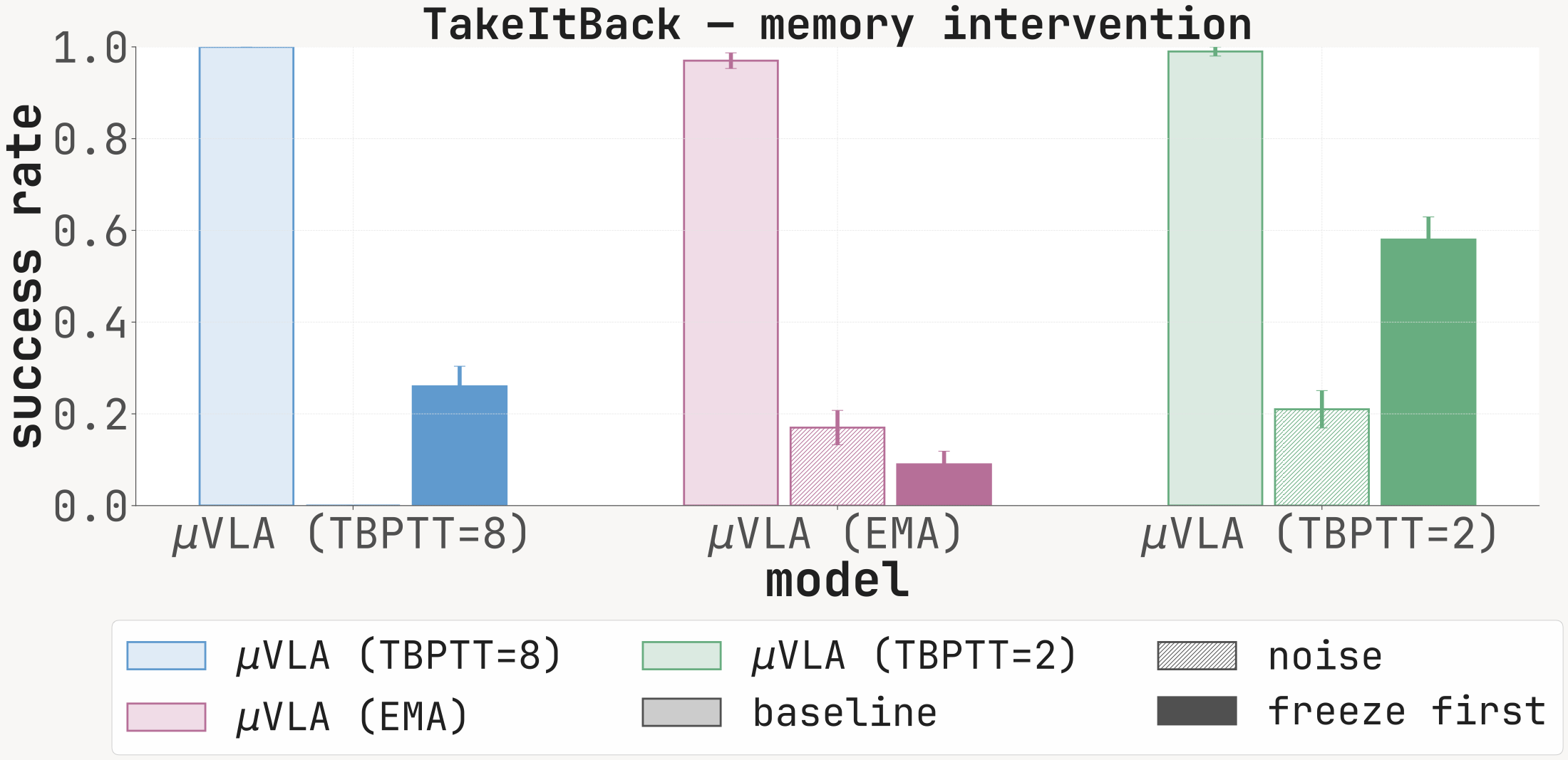
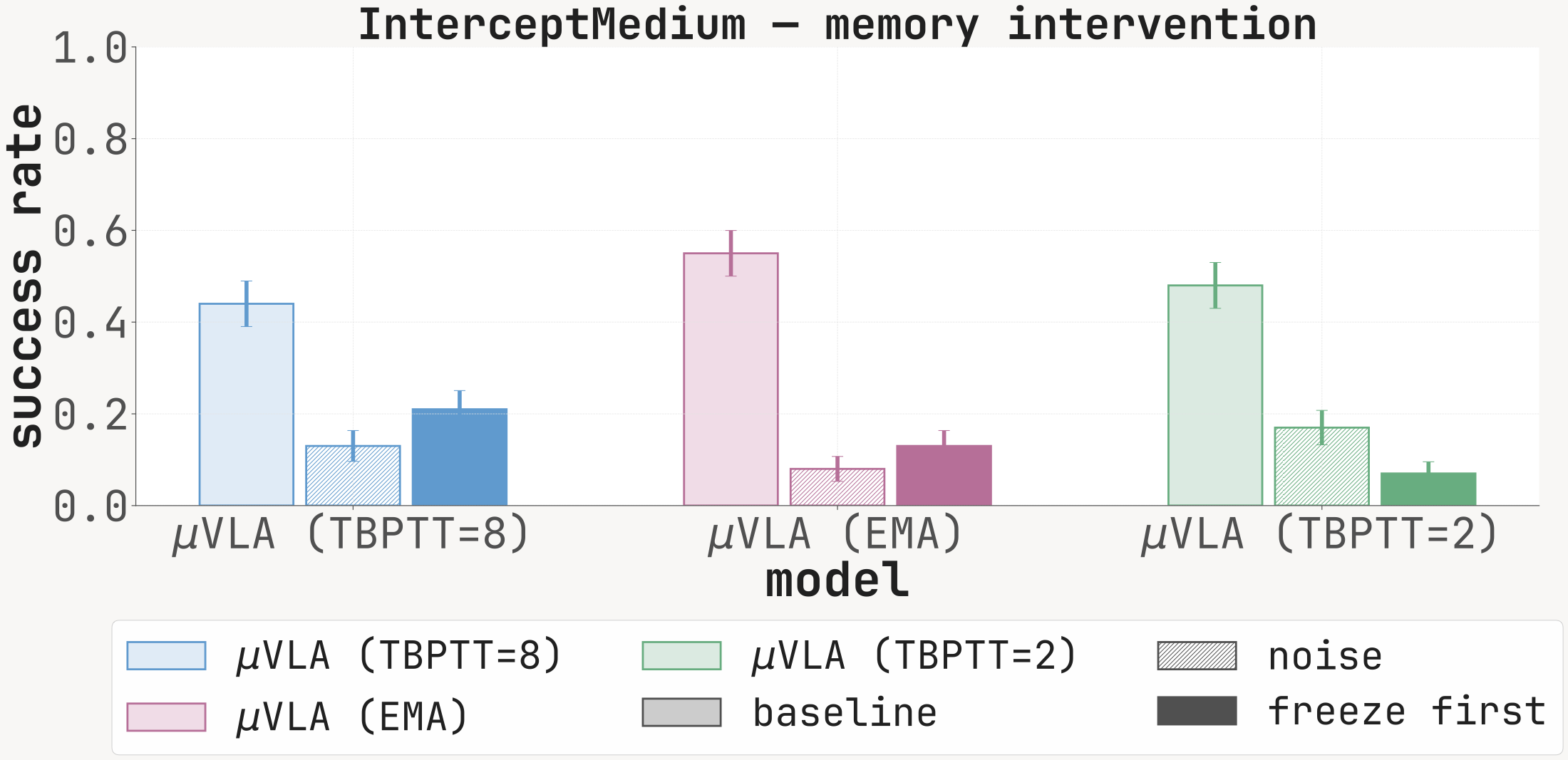
Success rate at 100 episodes under baseline (clean memory), noise (Mt replaced with i.i.d. Gaussian noise before every forward), and freeze_first (memory locked to M1). The noise condition drops SR sharply on every cell with a non-trivial baseline, confirming that the recurrent channel is functionally read at inference.
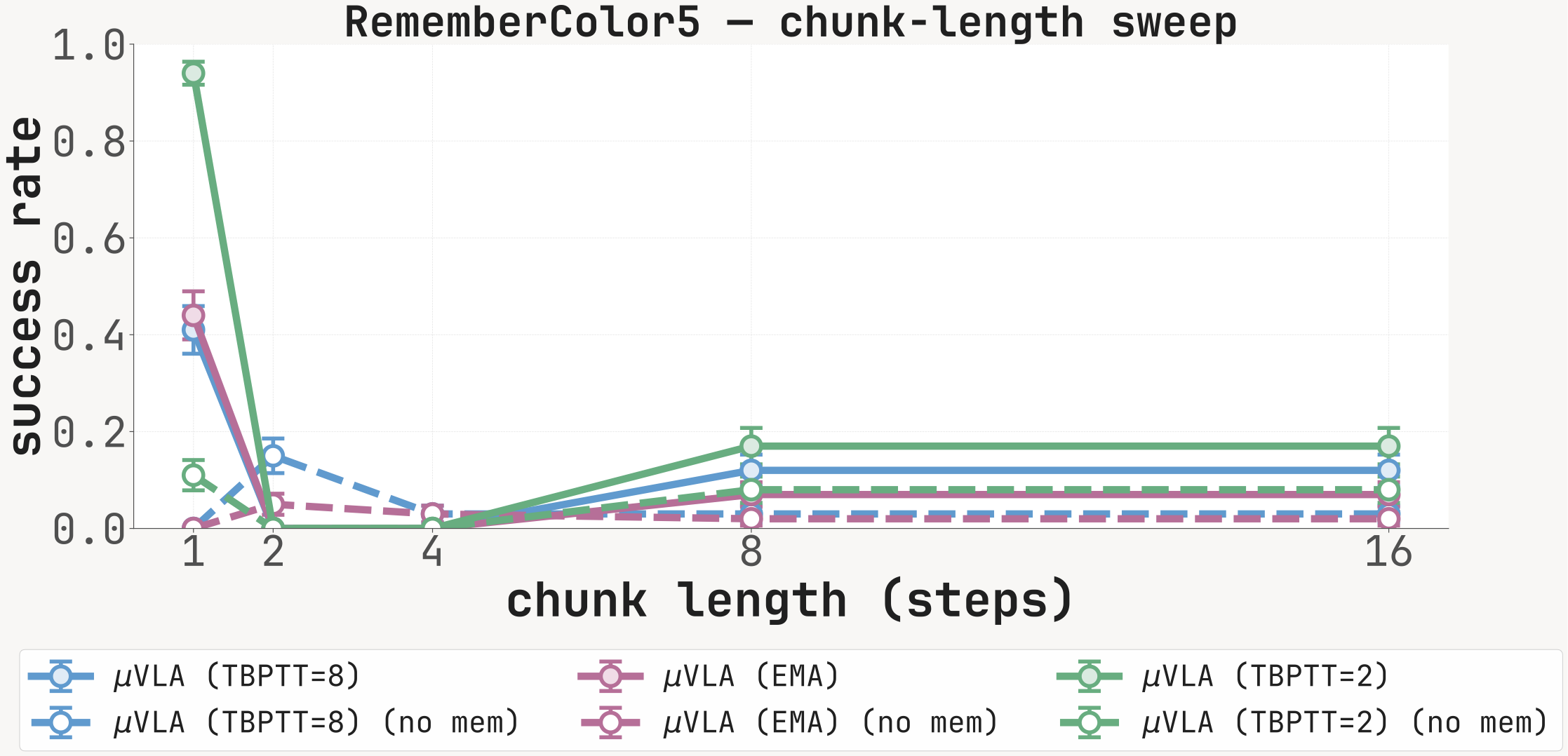
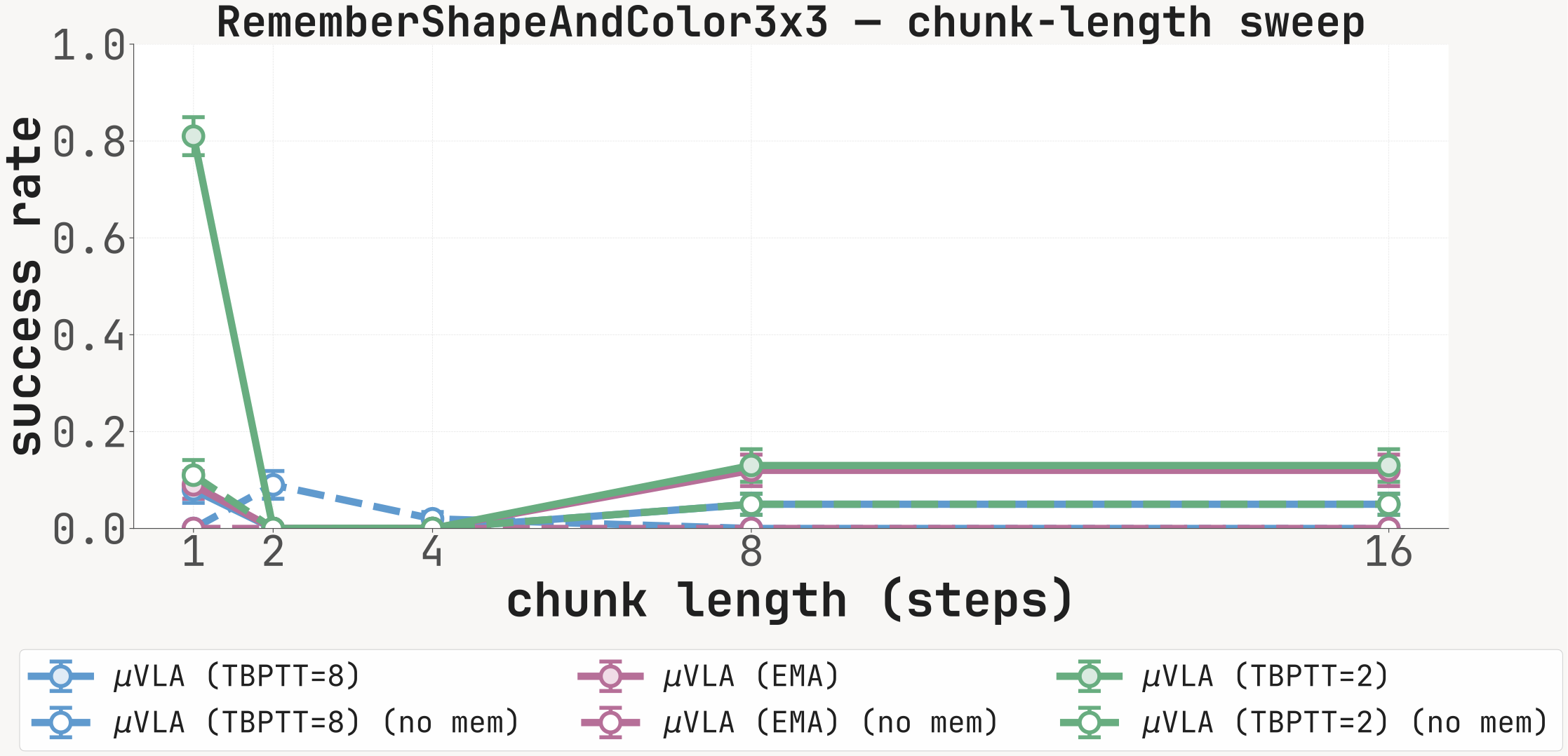
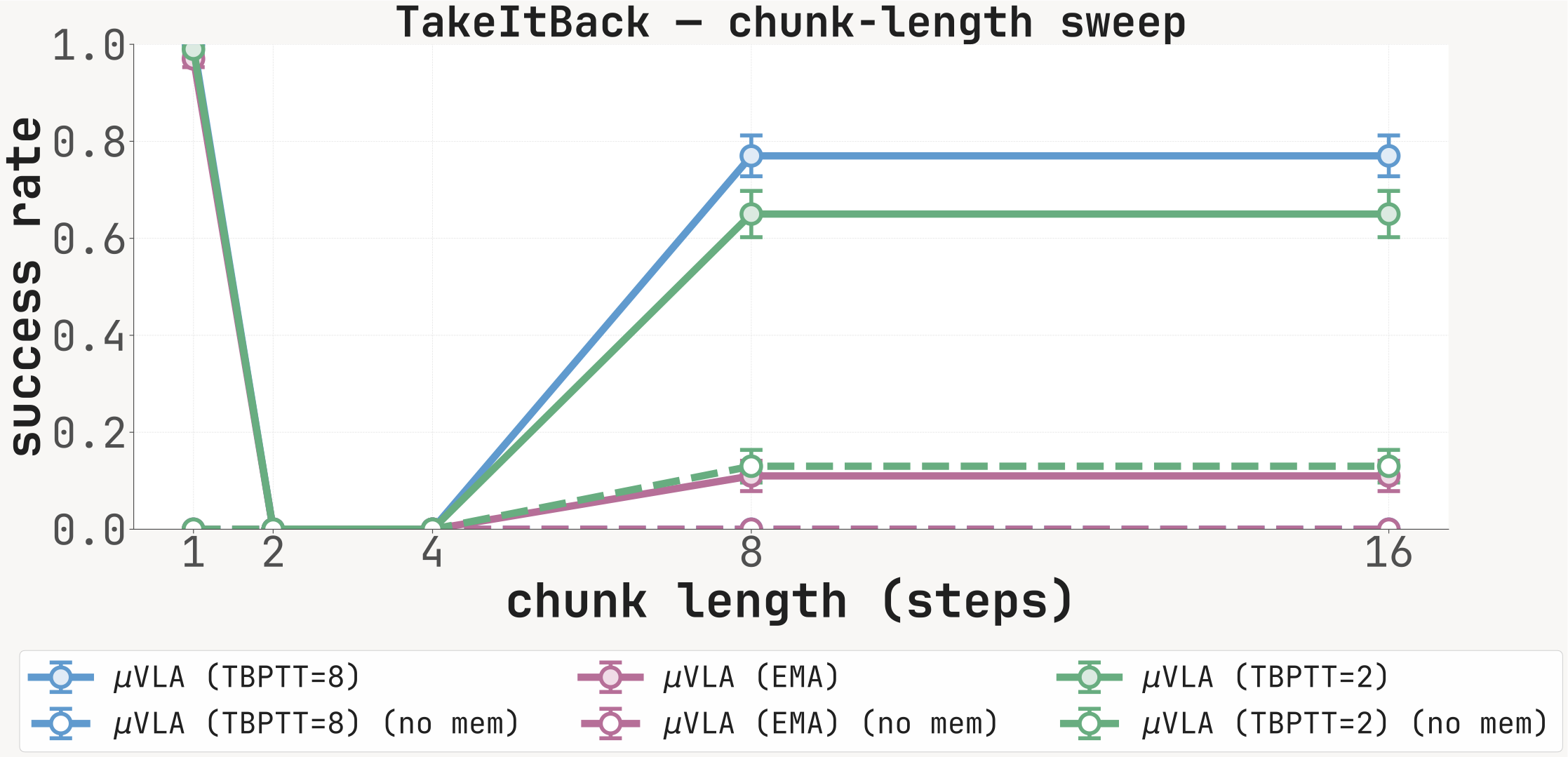
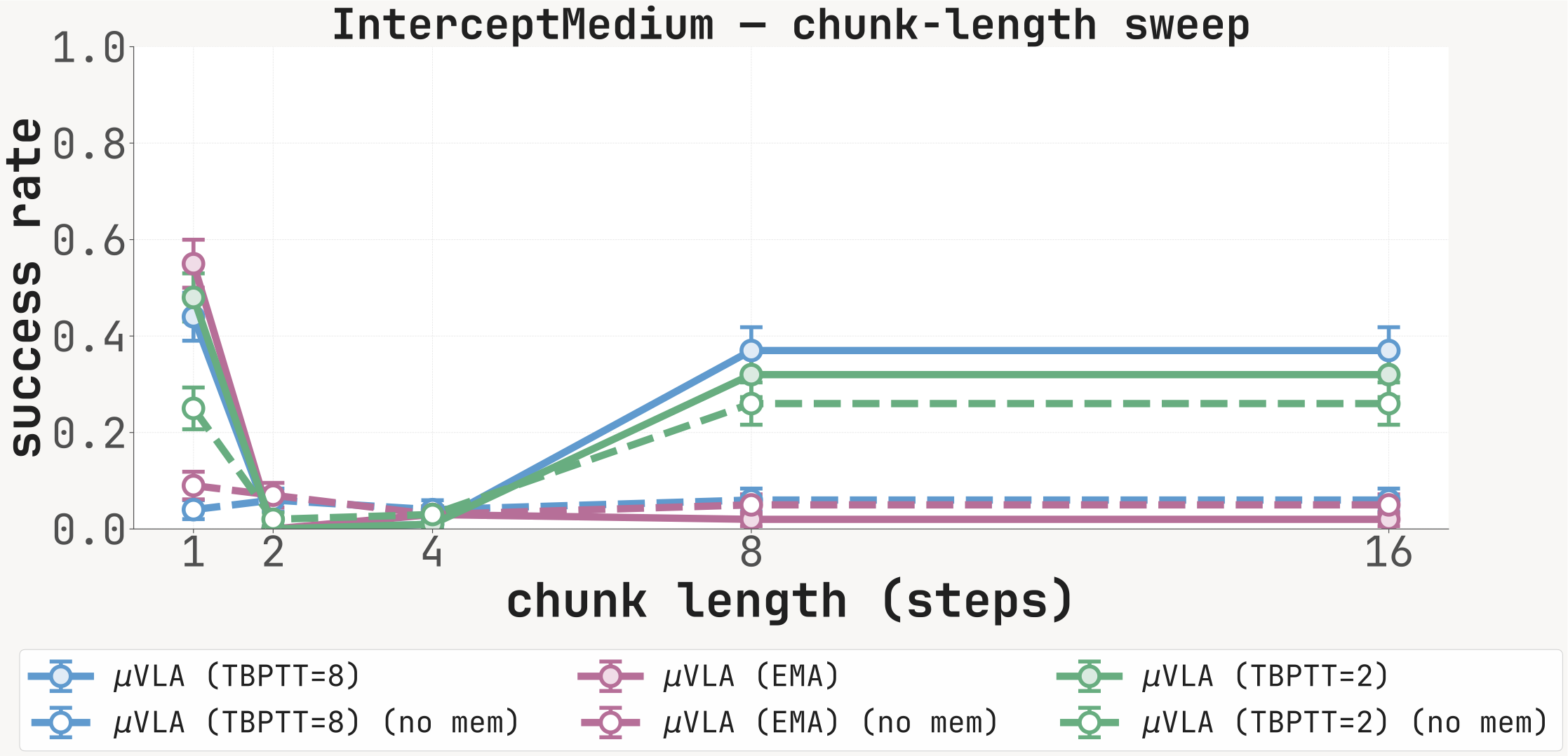
For each carrier (K=8, EMA, K=2) we report SR at chunk lengths {1, 2, 4, 8, 16} with the memory channel active (solid) and zeroed at inference (dashed). The with-memory minus no-memory gap is largest at chunk=1 on cue-recall tasks; long-chunk inference partially bypasses the recurrent channel.

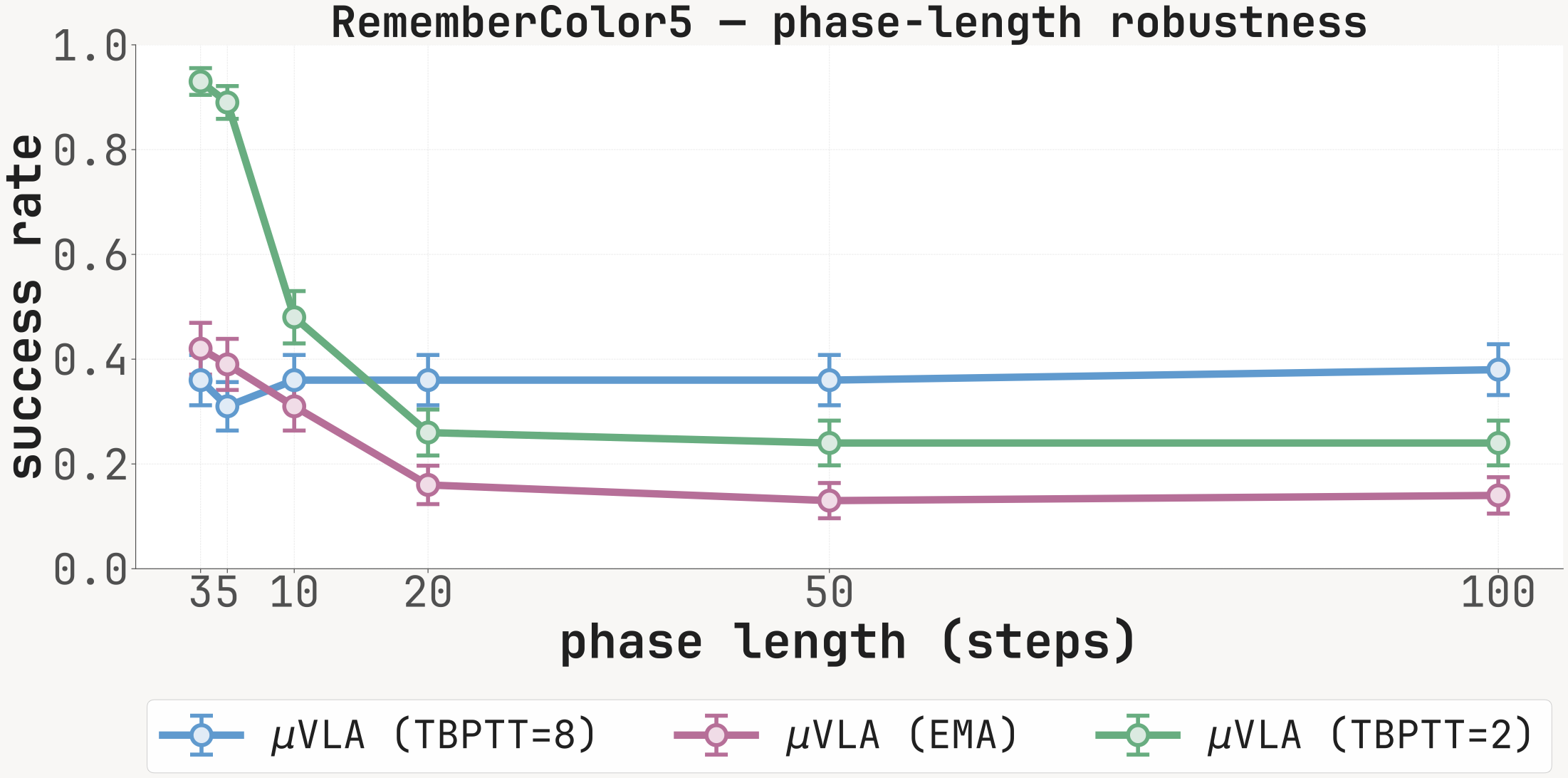
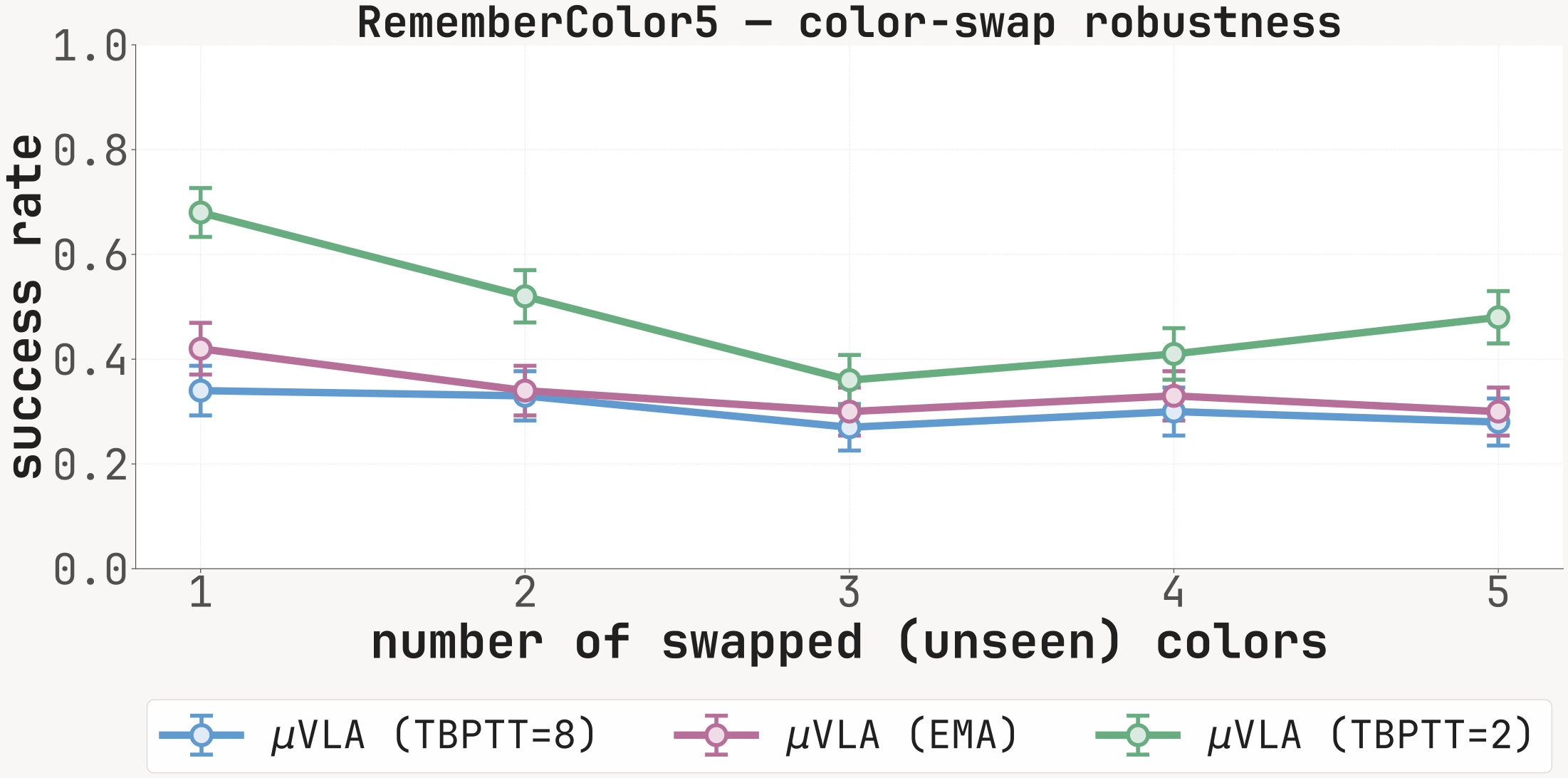
(a) Both task phases fixed to N∈{3, 5, 10, 20, 50, 100} steps; training covers N∈{1,…,5} per phase. (b) 1–5 in-distribution colors replaced with the OOD palette {Pink, Orange, Purple, Brown, White}. K=2 dominates in-distribution and remains most robust to color swap, but degrades fastest with phase length; K=8 is flat-but-low; EMA collapses with phase length.